
People, Places and Things
In our medical document processing pipeline, we extract the potential sources or “origins“ of the document. This could be any medical practitioner or a health organization. For many of our customers we extract the most relevant document origin, however many customers now need to extract both the author and the facility from their documents. This motivated the need for origin re-classification in our pipeline.
# List of extracted origins
[
{
"confidence_score": 0.999023
"origin": "Alice Smith, M.D."
},
{
"confidence_score": 0.98738
"origin": "Toronto General Hospital"
},
{
"confidence_score": 0.783632
"origin": "New York City"
}
]
# "Alice Smith" -> "Person"
# "Toronto General Hospital" -> "Organization"
# "New York City" -> "Other"Using Gemini for Named Entity Recognition (NER)
Our initial approach was to create a prompt that takes an origin ex. “Alice Smith“ and asks Gemini to classify it as either “Person“, “Organization“, or “Other“. We described the output JSON format in the prompt itself. We started our experiments with Gemini-2.0-Pro to run the prompt, and we iterated through the list of origin entities. We also asked it to generate the confidence score.
for text in texts:
prompt = f"""Extract named entities from the following text and return them in JSON format.
For each entity, provide:
- text (string)
- category (e.g., Person, Organization, Location)
- confidenceScore (float between 0 and 1, estimate if unknown)
Text:
\\"{text}\\"
Respond with:
{{ "entities": [{{ "text": "...", "category": "...", "confidenceScore": ... }}] }}We compared the results with Azure Health Analytics, a previous API we were using for reclassifying existing entities on our entity types. We immediately noticed that Gemini-2.0-Pro was far slower than Health Analytics. For each origin, Health Analytics was taking 3 - 7 seconds to generate a response while Gemini-2.0-Pro would take 30 - 60 seconds.
In the next attempt, we tried running Gemini only once by providing a list of all entities as input in the prompt. The reasoning behind this choice was to cut out the time it took to initialize a connection with Gemini by minimizing how many calls were made.
"""You are an NER (Named Entity Recognition) Model. Given a list of string you return a
JSON array of entities. For each entity, determine if it is a person, organization or something else
Return:
- "text": the exact phrase from the input
- "category": one of ["Person", "Organization", "Other"]
- "confidenceScore": a number between 0.0 and 1.0
List of entity strings:
{entity_list}
Respond ONLY with a list of valid JSON for each entity:
{{
"text": "Dr. Alice Smith",
"category": "Person",
"confidenceScore": 0.97
}}"""This did not result in a significant decrease in speed. Gemini still took between 19-50 seconds on average for each item in the list. Moreover, when we classified the origins separately, Gemini took a little bit longer but the categorization was at least independent. When they were all combined the NER seemed to take into account the other entities and got confused when there was an overlap of words ex. John Hospital: “Organization“ -> John: “Person“ “Organization“.
We then switched our model to Gemini 2.0 Flash. There was a great improvement on speed (2-3 seconds, faster than Health Analytics) without affecting the accuracy. Furthermore, Gemini’s overall NER performance surpassed that of Health Analytics. For some organizations with more obscure names, health analytics consistently labelled them as “Locations” but Gemini was able to classify them as “Organizations“.
Using Enum Response Schema
Gemini has a feature that allows you to restrict the output to a list of possible options using enums. Forcing this structure made parsing the output a lot cleaner, since we no longer had to verify that the output was proper json. We also experimented with adding an additional category “Location“. This helped a bit with accuracy since we wanted to distinguish locations from names of people or organization (ex. “Toronto, Ontario“ has similar punctuation to “Smith, John“).
"""
You are an NER (Named Entity Recognition) Model. Given an entity, determine if it is a person, organization or something else
Entity: {entity}
Return "category": one of ["Person", "Organization", "Location", "Other"]
Alice Smith, MD : "Person"
John Pierre : "Person"
St. Mary's Hospital : "Organization"
Ontario Health Services : "Organization"
Toronto, ON : "Location"
Ottawa : "Location"
""" A final improvement to the prompt involved adding more examples that mimicked the format of some origins in the dataset. This helped the model recognize medical titles ex. “Alice Smith, M.D.“.
Testing Accuracy and Speed
We initially tested our accuracy on a dataset of 120 origins with 44 “Person“ origins, 69 “Organization“ origins, and 9 “Other/Location“ entities. We tried to include variety in each of the categories. Some of the person origins might have a middle name ex. “Alice H. Smith”. Some had the last name come first ex. “Smith, Alice“. There were many people with abbreviations of their title i.e. “M.D.” or “R.N.“. The organizations also came in many different formats. Some were just a single word “ Athena“. Some had four words “Toronto Metropolitan Insurance Company“. A few included organization abbreviations ex. “, LLC.“.
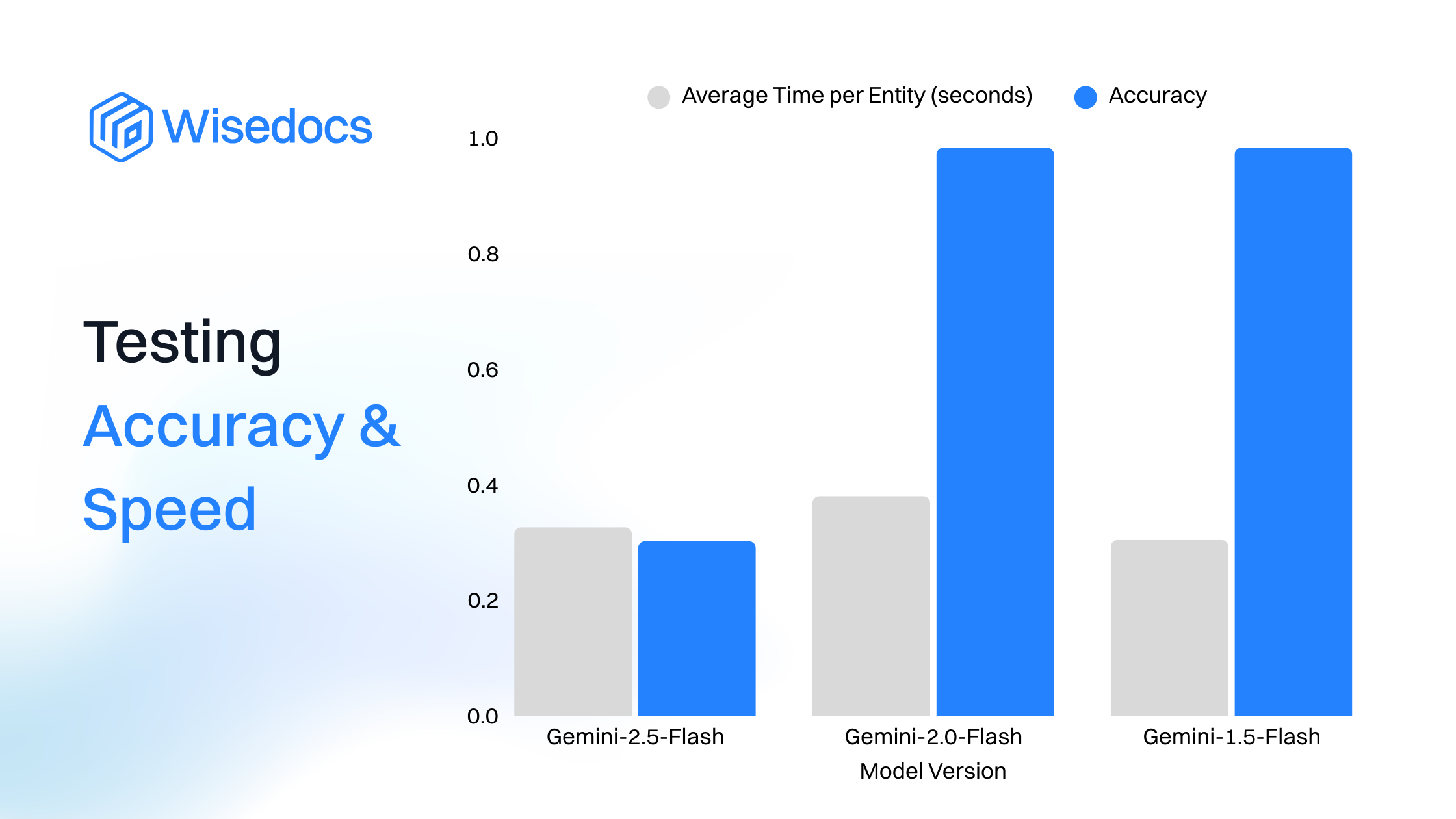
General Observations When Testing
- Gemini-1.5 and Gemini-2.0 struggled with organizations that have one word names. Gemini-2.0 performed slightly better on these type of entities
"Athena": "Person"
“Ethos” : Other- Gemini-1.5 and Gemini-2.0 also struggled with people that had titles it did not recognize or when there were multiple titles
"John, CMA" : Other
"John, Smith, MD, PLLC": Organization- Gemini 2.5 over classified people and organizations as locations. If the format of a person entity deviated from the one-shot examples it would be misclassified. Organizations without explicit relation to medicine or health would also be misclassified
"Ontario Chiropractic Group": Other
"John Pizza": LocationAdd More Context in Prompt
In another attempt we added more context about the type of a people and organizations in our problem. We described how the origins are the potential sources for medical and insurance documents. These sources includes doctors, nurses, medical organizations and insurance organizations. We also removed the “Location“ category since it seemed to cause more confusion with commas in people’s names
You are an NER (Named Entity Recognition) Model. You are given entities that might represent the source for medical insurance documents
These sources could include doctors, nurses, medical organizations and insurance organizations. There may also be mistakes and the entity
might not be a valid source. Given an entity, determine if it is a person, organization or neither.
Entity: {entity}
Return its "category" i.e. one of ["Person", "Organization", "Other"]
Examples:
Alice Smith, MD : "Person"
John Pierre, RN : "Person"
St. Mary's Hospital : "Organization"
Ontario Health Services : "Organization"
Toronto, ON : "Other"
OWOEDKSD : "Other"Issues with one-word organizations were fixed by this change in Gemini 1.5 and Gemini 2.0. The only cases that weren’t fixed by this change was an acronym for an obscure organization and a person with two titles: “M.D., PLLC.“. Since PLLC is often associated with organizations it makes sense that Gemini misclassified the origin as an “Organization”
Without the “Location“ category Gemini 2.5 classified some organizations as people. It was very sensitive to small punctuation errors that did not greatly change the semantic meaning of the entity ex. “Medical Risk Services, LLC“ → “Person“, “John A. Smith, MD” → “Other“. If it didn’t fit the one-shot cases, a “Person” was classified as an “Other”.
Logging for Cost Estimations
As a small side note, Gemini is able to report token usage data. We found this to be useful for tracking our usage of Gemini and estimating costs. The usage metadata is found as a field in the response object. These logs can be queried in a monitoring software like Grafana.
f"Input tokens: {response.usage_metadata.prompt_token_count or 0}\n"
f"Output tokens: {response.usage_metadata.candidates_token_count or 0}\n"
f"Thinking tokens: {response.usage_metadata.thoughts_token_count or 0}\n"
f"Cached tokens: {response.usage_metadata.cached_content_token_count or 0}"
Takeaways
Overall, it is important to choose the right type of model for your problem. Some problems need a light weight model like Gemini-2.0-flash over a heavier model like Gemini-2.0-pro. The difference in speed can be very significant. If you aren’t sacrificing accuracy, then a lightweight model may be more appropriate for your purposes.
Always try to test with multiple models and multiple versions of the model. We did not expect Gemini-2.0-flash to outperform Gemini-2.5-flash but it did! As Gemini-3.0-flash and flash-lite are on the horizon, we'll test our evaluations for the performance as we upgrade our models. It’s important to provide context in your prompt about the problem that is being solved. It can significantly improve your results, especially for your edge cases. When you’re data comes in an industry specific format you should try to include multiple examples in the prompt that cover these cases i.e. the addition of “M.D.“ to the “Person“ origin examples.
Make sure your test dataset covers the diversity of your actual real-world data. Having variety in our testing data helps you identify the strengths and weaknesses of your model. It provides guidance on how a prompt can be improved upon.
Future Work
Improvements could be made to make the model less sensitive to typos, small grammar and punctuation mistakes. Our data often contains abbreviations of medical titles (i.e. “M.D”, “PLLC.”). Fine tuning would be able to teach Gemini to identify these common titles.
Another potential approach would be to add RAG into our model’s pipeline. Some smaller insurance companies have names that do not include keywords like “organization“, “company“, “insurance“, “medical“, etc. that would make it clear that it is an organization.
A quick internet search can clarify whether an origin is a person or an organization ex. “Athena“. It can also provide context about common shorthands for organization names (i.e. “WHO” for “World Health Organization” or “John Hopkins” for “John Hoskins Medical School“.
Industry specific titles like “M.D.“ and “CMA“ are also easy to verify with a lookup. Incorporating RAG could strength the industry specific knowledge of the model and greatly improve accuracy.
As new models and use-cases continue to evolve we'll compare how heavy of a lift we need to make to a use-case in the following buckets:
- Prompting
- Prompting + PrevGen Model
- Finetuning Commercial LLM
- Finetuning Local LLM
- More comprehensive LLM System (ex RAG)

.png)