
Over the past few months, Wisedocs has been rebuilding our organization’s Machine Learning (ML) pipeline. As a platform that processes medical claims, we help facilitate the generation of case reports for various users, including medical professionals, claims adjusters, and government agencies. The key question facing us was how to rebuild this pipeline to support 100x the scale. This article outlines some of the key lessons we learned during this process.

Our previous pipeline, built in 2021, faced some key challenges, including slower speeds in adding or updating modules and limited economies of scale. To this effect, some of the broader goals of the rebuild included:
- Clear process tracking and traceability
- Eliminating tech debt
- Supporting 100x our current scale
- Reducing debugging and feature release time
The process was challenging and interesting, and this article shares some of the key lessons we’re taking with us for future projects.
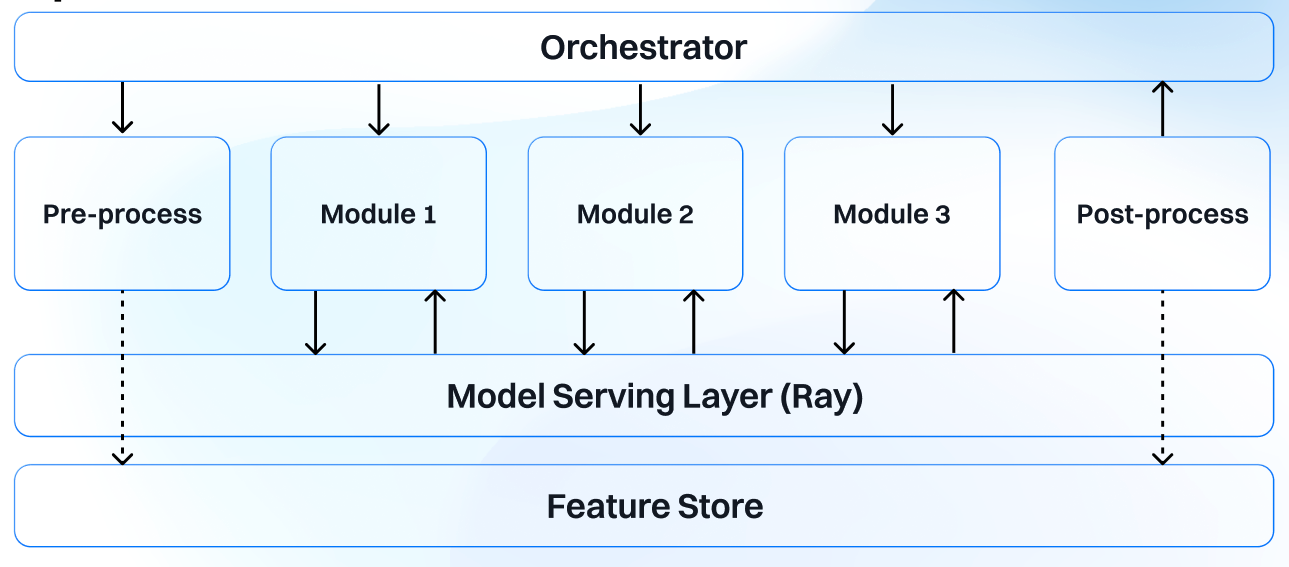
This diagram is a high-level architecture of our new Kubernetes-native Machine Learning pipeline. We chose Temporal as our orchestrator and have our fine-tuned models being served with Ray Serve. Each module represents a step in our machine learning pipeline, whether it is feature extraction, page stream segmentation, or document classification.
1. Time Spent Planning is Never Wasted
This may seem obvious, but it's easy to skip when you're eager to build. You can either spend time planning upfront—or pay for it later through painful rework and patching. Planning should include:
- Defining Success Metrics: For us, success meant replicating the results of the original pipeline, creating a highly modularized design supporting heterogeneous models, adding an ability to support custom workflows, and reducing job latency through parallelization and GPU inferencing.
- Designing and Drawing the System Architecture: Drawing diagrams helped us finalize module responsibilities, technology choices, and how data would flow and get manipulated throughout the system. It allowed us to design specific and specialized components that were solely responsible for each indexing task, reducing debugging and error-tracing times.
- Sharing and Debating Schemas Early: Especially in open-ended projects, different engineers may have different interpretations of the same requirements. SOLID principles are helpful, but not prescriptive. Debating interfaces, responsibilities, and data contracts before implementation saved us countless integration headaches.
2. Choose the Right Tools
One of our most consequential decisions was selecting a pipeline orchestrator. The choices were numerous - Sagemaker, Airflow, Kubeflow, Ray, Temporal, Prefect, and so many more - this was overwhelming. This abundance of choice is a common feature in today’s technological landscape, making the selection of the right tool seem like an incredibly daunting task. Here are a few ideas that can help with this process:
Define What You Absolutely Need
Mono-Repository vs. Module-Specific Repositories
One of the major changes we changes we made in the new pipeline was a migration from a multi-repository structure to a mono-repository structure. Below is how our mono-repository is structured:

The pipeline folder has subfolders that handle the orchestration logic and build processes for workers and the workflow API. The shared library has all of our utility functions, further subdivided into PDF Processing, Image Processing, Schema definitions, and so on. The modules include responsibilities such as title prediction, date prediction, page stream segmentation, and many more. The serving layer is responsible for model serving and is further subdivided by entity. Finally, we have a folder with code that supports our CI.
One of our core goals in this migration was to eliminate technical debt and make each module singly responsible for its specific task. In our old architecture, each repository had its own utility functions for image and PDF processing, using GenAI clients, and working with OCR data. We were able to separate shared code into a shared library module and reduce the scope of responsibility for each module.

For example, before, our page stream segmentation repository would take in a file and was responsible for document splitting, preprocessing data, model serving, post-processing predictions, and synthesizing documents. In contrast, the PSS module in our mono-repository is solely responsible for taking in an input of two pages to request for the prediction. This design allows modules to be more effectively unit tested for their responsibility, while the mono-repository structure also allows for effective integration and end-to-end testing.
Finally, in a world of generative AI, sharing all modules in a mono-repository means all modules are within a shared context window, which allows for better dependency tracing and usage of Generative AI tools for coding.
Temporal as our Orchestrator
When choosing an orchestrator, we asked ourselves: Do we need to support pause/resume for workflows? Is a strong UI essential or a nice-to-have? Do we prefer a large developer community or newer cutting-edge features? We broke requirements into must-haves, strong wants, and nice-to-haves. With this list in mind, we perused documentation and determined what is supported by each available option. This helped narrow our list down to a few top contenders. Here is a table of some of our priorities when we were choosing an orchestrator:

Ray Serve for our Model Serving
Similarly, when we chose Ray Serve for model-serving, we had a few features that we absolutely loved. Ray Serve integrated very well with our Kubernetes-native pipeline. It supported heterogeneous models and online serving, which allowed us to deliver low-latency predictions. Moreover, Ray allowed for fractional utilization of GPUs and had native support for advanced scaling, which permitted a more efficient allocation of resources.

Yet another feature I would like to spotlight is Ray multiplexing. It is an optimization technique that allows us to host multiple models with the same input type on a shared pool of resources (cluster). This feature, paired with Ray's multi-cluster support meant that we could (1) deploy a cluster for each specific module and (2) efficiently route between various models within each Ray cluster based on customer configurations.
Imagine you have three groups of models for three indexing tasks, each of which takes a different input. Our orchestrator allows us to efficiently route the request to the appropriate Ray Cluster, while Ray multiplexing allows for routing to the specific model that needs to execute the request within the cluster e.g. model A or B for Task 1.
Build Toy Projects with Shortlisted Tools
This was critical. We built mini-pipelines in each tool and tested real use cases. It was really easy to get excited about certain orchestrators, only to realize some promised features were more cumbersome and pedantic to use in practice. In this process, we ran and resolved 100+ issues; here are just three of them:
- We realized that Temporal had a 2MB payload limit on inputs and outputs; in practice, our payloads can be significantly larger. Thus, we amended our design to use S3 external storage and began ingesting and returning S3 references to the payload instead. Funnily enough, we then encountered an error whereby sometimes we returned too many payload references at once, hitting the 2MB payload limit once again. To resolve this, we began to return the parent directory of all payloads whenever we needed to return more than one payload reference. By using this "reference to references" approach, we were able to guarantee that each activity and workflow returned only one reference, ensuring we are always comfortably within the 2MB threshold.
- We realized Temporal did not preserve the order (FIFO) of workflows/tasks that entered. This is important to us, as ideally, we would want documents that enter the pipeline earlier to leave earlier as well. To this effect, we add a rate limiter to preserve some sense of order between entry and release.
- We realized that any block of code that has an execution time of greater than 2s must be within a Temporal activity. If it is not, Temporal considers the workflow to be in a potential deadlock and makes no progress. To resolve this, we defined new Temporal activities that wrapped around any longer-running orchestration logic. This permanently resolved the error.
Completing this toy project process gives you a real feel for each option and allows you to make a confident final decision for the main build.
Measure Your Improvements
With the success metrics defined earlier, you should be able to measure and track your improvements. This should provide further indication that you have chosen the right tools. Here are some key ways we improved our ML pipeline:
- Up to 20x faster processing times for cases
- Supports processing files up to 10× larger (page count)
- 50% fewer lines of code
- Up to 64% reduction in memory consumption for certain modules

3. Keep Your North Star in Sight
New builds are an iterative process. At Wisedocs, we often aim to Get It Done Right— not just building to requirements, but doing so in a way that is extensible, scalable, and valuable to our customers. Getting it done right, however, might mean continuous iterating and refining of earlier versions of a product, and this can quickly feel repetitive. While robust planning alleviated a lot of this burden, staying grounded in our "why" also helped. We want to deliver fast, accurate document processing at any scale. This vision pushed us to prioritize architectural modularity, allowing each component to take on a single responsibility, scale independently, and minimize systemic risk. If we were moving closer to that ideal—even incrementally—it meant we were on the right track.
Rebuilding a core legacy system is never just a technical challenge—it’s a strategic one. The right mindset, tooling, and processes are what separate a rushed rewrite from a resilient foundation that can support future growth.
It is important to remember that testing is not optional, but essential to have a clear and well-defined migration strategy. To this end, we ran comprehensive unit tests and automated a lot of our CI. Additionally, we created a seamless way to run the old and new pipelines in shadow mode, allowing us to toggle which pipeline's output the customer received instantaneously. This allowed us to migrate customers according to their risk profile, to proactively address any issues, and to catch the 1 in a million bugs.
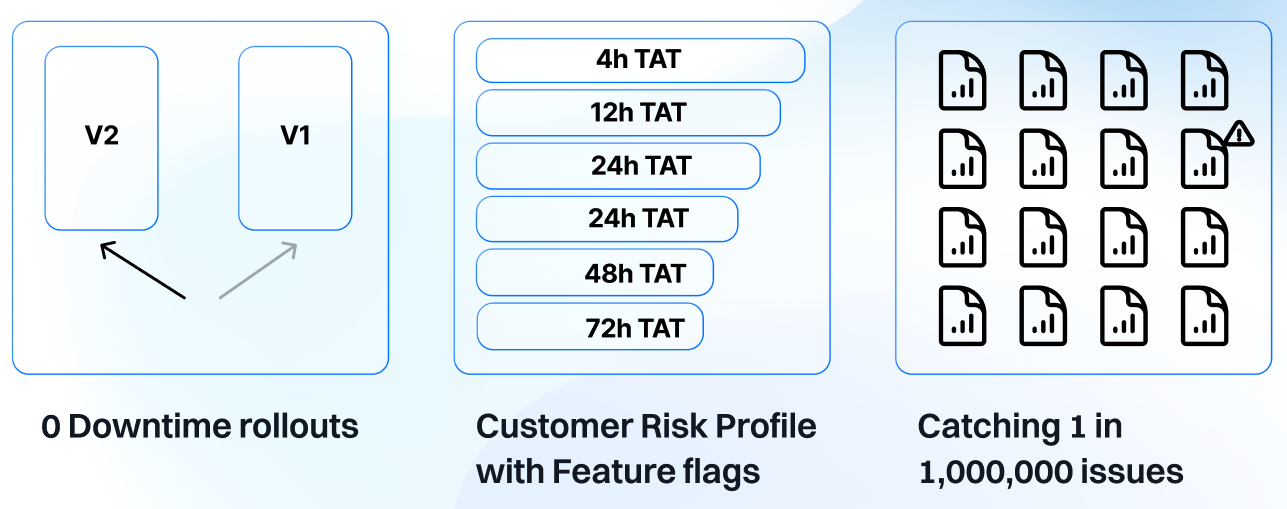
More specifically, below is a glance at what our migration strategy looked like. Firstly, we worked on building a MVP that passed various unit tests and ran on some smoke tests we had identified as being representative of our case distribution. Next, we moved forward with deploying the pipeline in shadow mode in our first customer region as this helped us identify and resolve several bugs without affecting the customer. Next, we switched customers over to using the new pipeline as the primary in customer groups (CGs) based on their risk profile, and finally, we were able to begin turning off the old pipeline. Once this process is complete for your first production region, subsequent regions should be easier and quicker.
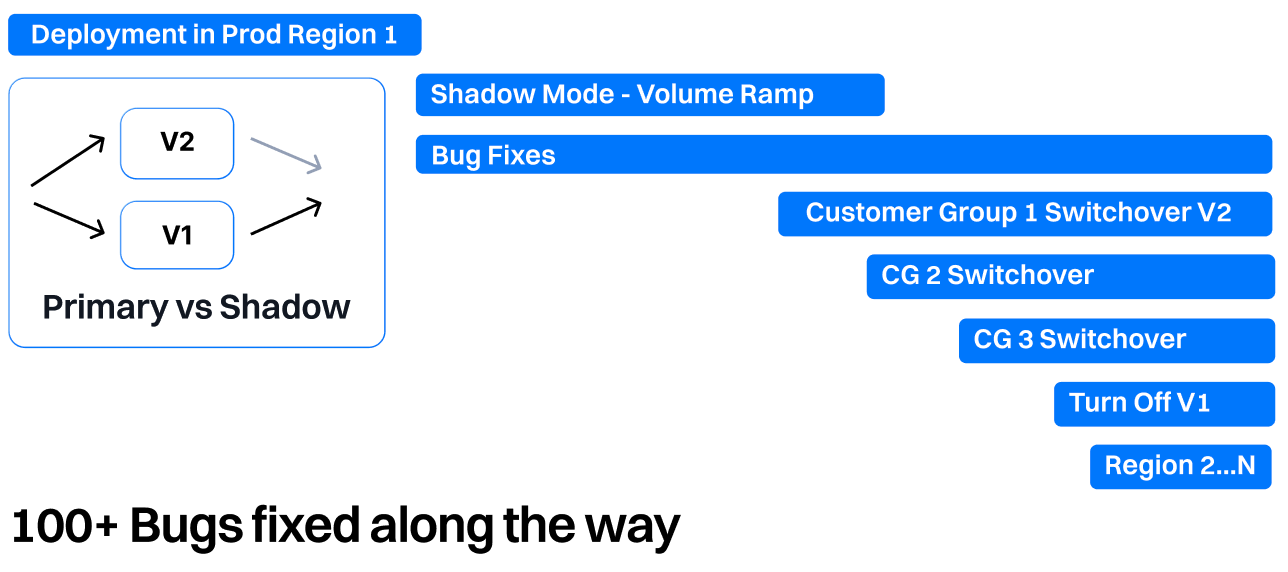
For anyone undertaking a similar rebuild: plan thoroughly, improve iteratively, and test continually to ensure your product aligns with the long-term core goals of both your business and your customers. Establish a well-defined testing and migration strategy in place to minimize the possibility of customer disruption and ensure a smooth transition.
Next Steps and Part Two of Rebuilding our ML Pipeline
We'll be releasing Part Two on rebuilding our ML pipeline, and we’ll share some of the most interesting bugs we encountered along the way in our rebuild journey.

.png)