A medical claims professional reading a 150-visit medical record does more than just search for specific facts, they’re reconstructing a story. They’re asking themself, what happened, in what order, and what it means for the patient and their claim. As model technology rapidly improves, the question of whether a model can build upon the role of the medical claims professional — understanding the entire context, following a thread throughout multiple medical visits, and coming to accurate conclusions — is increasingly important to answer.
We’re excited to share the Medical Long Context Reasoning (MLCR) benchmark. New models continue to push the frontier of knowledge work. Measuring their capabilities on real-world problems helps us answer the question: can models reason through long, complex medical claims?
We’re introducing MLCR to test model effectiveness for the types of questions many professionals ask when reviewing medical cases while dealing with longer document lengths. Our contributions include:
- Creating a difficulty benchmark for realistic knowledge work tested across six tiers of difficulty
- Open sourcing 10 synthetic medical case summaries based on real world compositions and 100+ questions (from the first three tiers of difficulty) that medical and adjacent professionals would think about.
- Providing access to questions in the three most difficult tiers available to model labs as a private evaluation for model development
- Building an open-source harness that injects realistic but intentionally irrelevant junk context using standard U.S. and Canadian medical forms.
The benchmark revealed a number of findings in how models process long context documents:
- Frontier models struggle with compound and expert tier questions
- Thinking assists in easier questions, but can be harmful for complex questions
- Reasoning across longer context lengths with filler contents slightly reduces accuracy
Methodology
Designing Cases for Long Context Reasoning
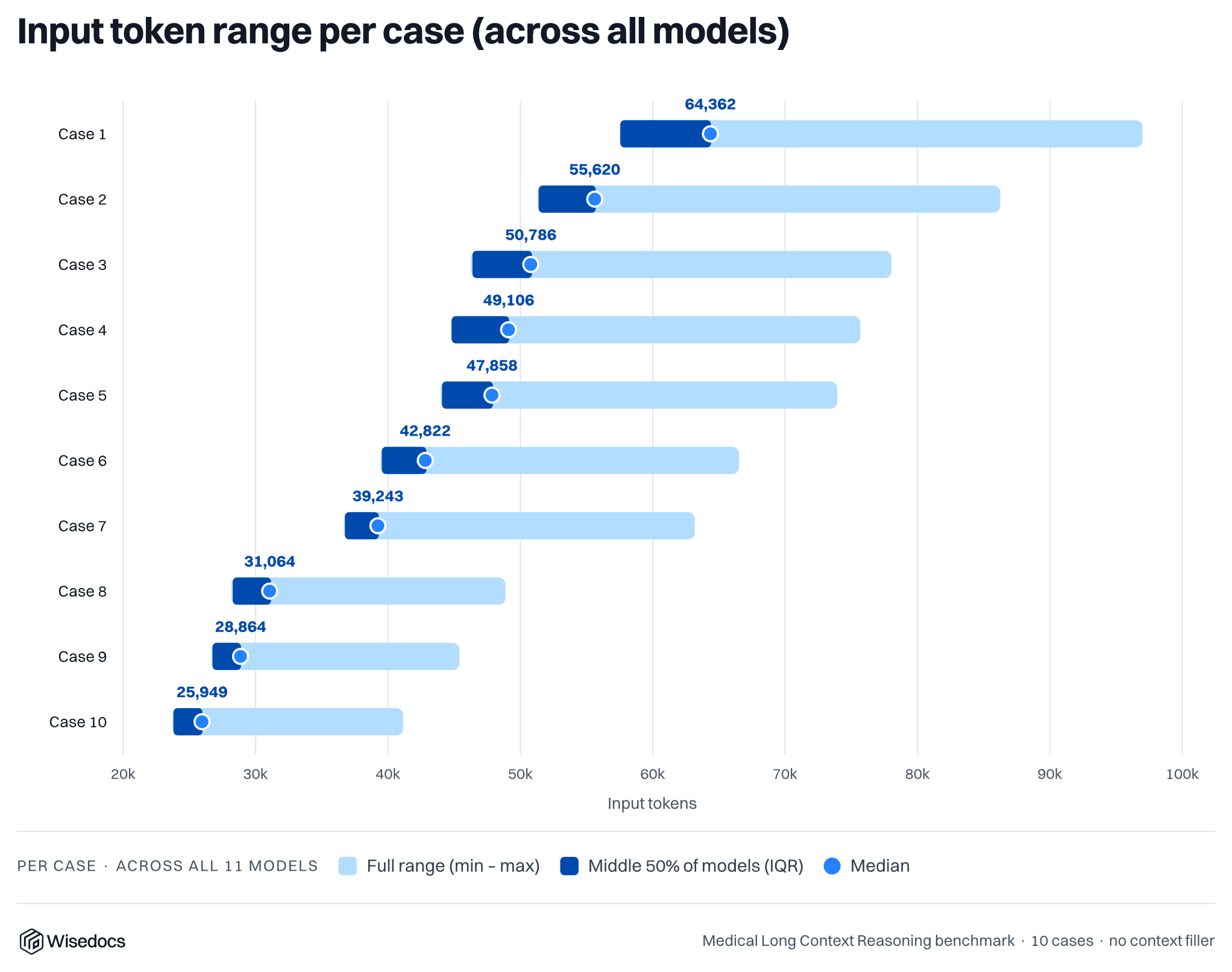
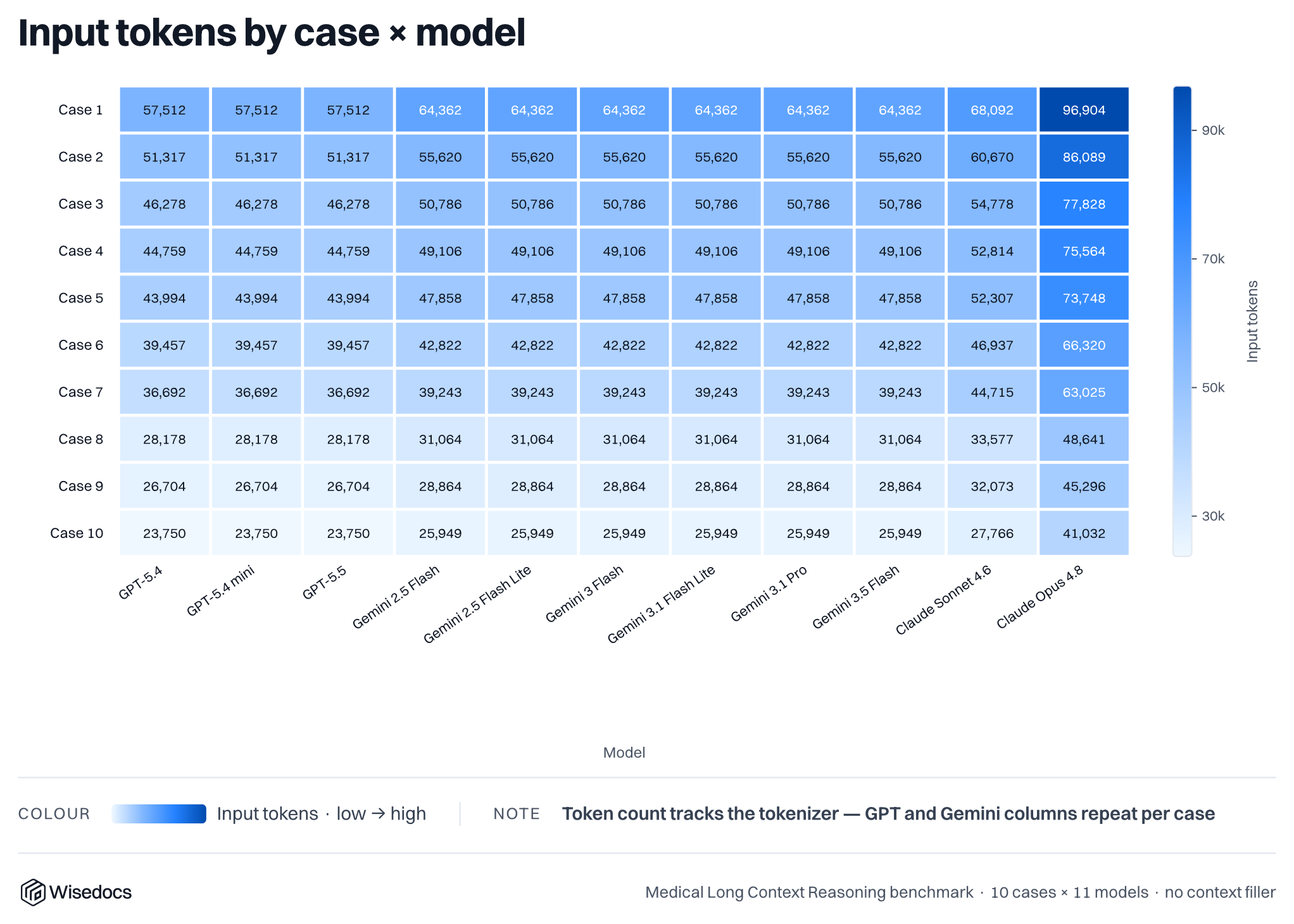
We built 10 synthetic, real-world inspired medical cases that are between 25k and 64k tokens in length. These cases consist of 50-150 medical summaries spanning across specialities. We then ask the large language models 250 questions across each of the 10 cases, categorized by difficulty. Once the baseline has been established, we run a series of experiments to measure the impact of additional junk context, simulating medical records with irrelevant information. We insert OCR (optical character recognition) text from common medical and insurance forms to fill up the context window of models to create a relevant needle-in-the-haystack style problems.

Designing Questions
Questions in the MLCR benchmark are organized into six difficulty tiers based on the type of case-wide synthesis reasoning required to answer them. Simple questions are direct questions and answers, while more complex questions require significant multi-hop reasoning and knowledge.
Tier 1 · Easy
Easy questions require locating a single, clearly labeled fact within the record. The answer typically appears in a structured field early in the case, such as the date of injury, mechanism of injury, occupation, or hospital admission dates. A model or human only needs to find the right field and read it. These questions establish the foundational facts of the claim.
Examples:
- What is the date and mechanism of injury?
- What is the length of hospital admission?
- How many days from the date of the injury to the last visit?
Tier 2 · Medium
Medium questions require locating and combining a small number of facts, sometimes spread across a few visits. The answer is still grounded in explicit documentation, but may require identifying the most recent instance of an occurrence, confirming a status, or pairing two related data points. This could be combining a surgery date with its outcome or an MMI declaration with the specialty that made it. Some judgment is needed to determine which documented instance is the relevant one.
Examples:
- What is MMI status and date?
- What were the total number of surgeries performed?
- What was the most recent work status?
- Describe the functional capacity evaluation results.
- What is their IME (Independent Medical Evaluation) count and causation conclusions?
- How many days were there from injury to MMI?
- What was the impairment rating?
Tier 3 · Hard
Hard questions require reading and reasoning across the full record.The answer cannot be found in a single visit and must be constructed by tracking a clinical thread from beginning to end, comparing information across multiple providers or time points, or identifying a pattern that only becomes visible when the entire case is considered together. These are the questions that most closely reflect the reasoning an experienced adjuster performs when reviewing a complex claim.
Examples:
- What was their longest treatment gap (requires computing intervals between every consecutive visit pair)?
- What was the count of specialty visits (requires categorizing every visit across 75 to 150 records)?
- How do the treating provider and IME disagree (requires reading both treating notes and IME reports and identifying where they diverge)?
- What is the diagnosis evolution (requires comparing the first and most recent clinical assessment)?

Tier 4 · Expert
Expert questions require full record synthesis combined with clinical judgment. The answer is not documented explicitly anywhere in the record — it must be reasoned from the overall clinical picture. These questions ask not just what happened, but why, and what it means. They reflect the kind of judgment an experienced adjuster or medical reviewer applies after reading an entire case file, and they are the hardest questions to score because the reasoning matters as much as the conclusion.
Examples:
- Why has the claimant not been able to return to work?
- What does a pattern of contradictory surgical recommendations reveal about clinical decision-making?
- What does a divergence across cognitive recovery domains suggest about the nature of the injury?
Tier 5 - Multi-part · Compound
Compound questions combine two or more independent sub-questions into a single prompt. This tests whether a model can handle a multi-part question without dropping one of the parts, conflating the answers, or letting context from one part bleed into another. In the real world, professionals rarely ask one question at a time — compound questions reflect how information is requested in practice.
Examples:
- Describe the injury basics and current functional status combined.
- What is their surgical history paired with post-surgical physical therapy count?
- Create a diagnosis chain paired with referral timing.
Tier 6 - Compound Hallucination Check
In most cases, reviewers don’t know what is present or absent in the case. To test for hallucinations, each prompt contains two questions: one that is answerable from the record, and one that is not documented anywhere in the case. The only correct response to the unanswerable part is to state that it is not documented. These questions were added after observing that models can generate plausible-sounding responses, but invented clinical details when pushed beyond what the record actually contained.
Examples:
- A documented medication paired with an undocumented specialist referral.
- A confirmed procedure outcome paired with a follow-up that never occurred.
Assessing answer correctness
For each case and question, we compare model-generated answers against human-validated answers using a panel of LLMs with a simple rubric of correctness, completeness, and conciseness. We utilize Opus 4.8, GPT-5.5, and Gemini 3.1 Pro as our judges and utilize a majority vote across the categories.
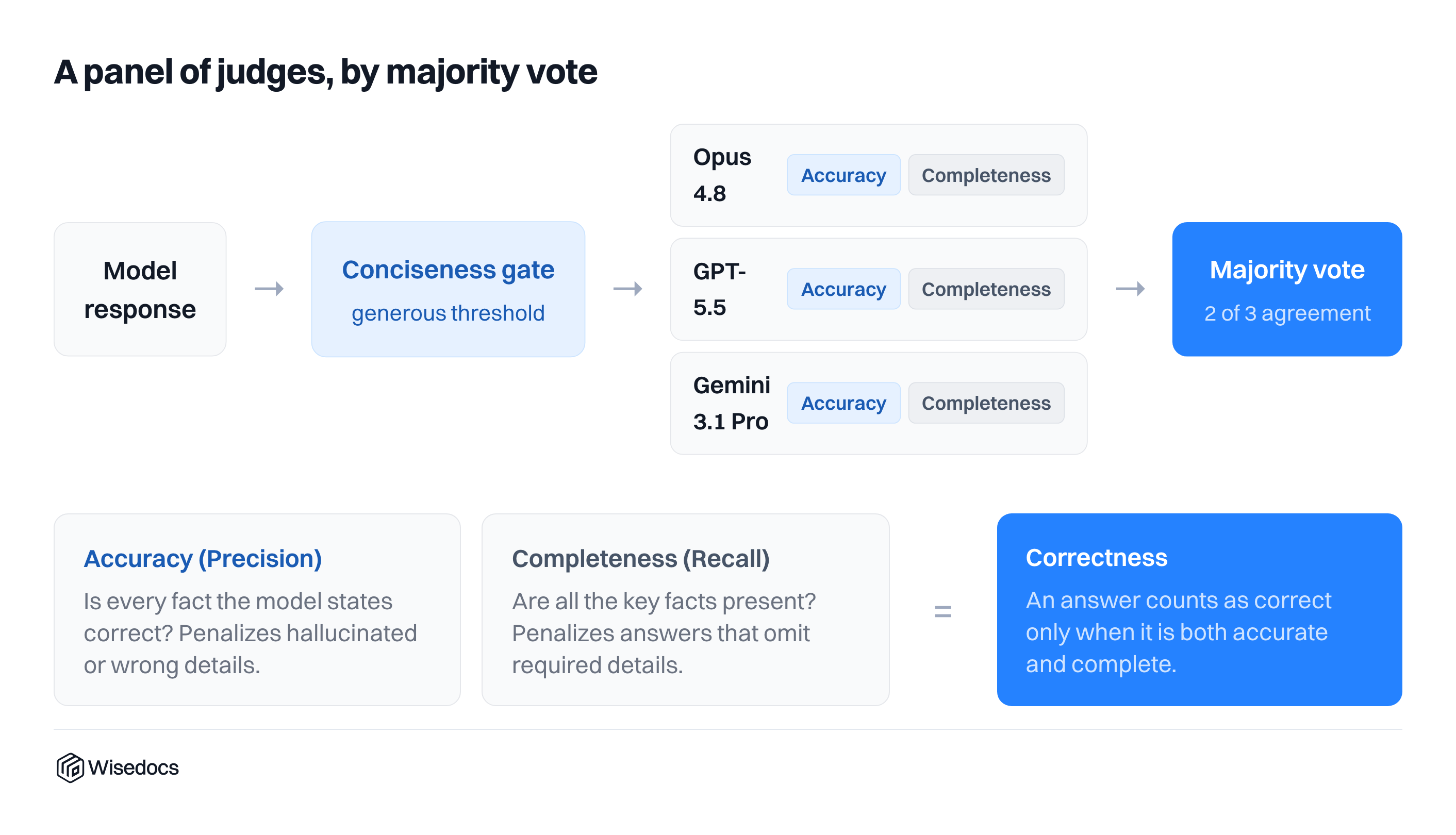
We calibrated our judges against a sample of human-validated questions before running them across the broader set of questions. Each judge evaluates responses along two dimensions: accuracy (precision) and completeness (recall). Accuracy measures whether every stated fact is correct, penalizing hallucinated or incorrect details. Completeness measures whether all key facts are present, penalizing answers that omit required information. A response is only counted as correct when it passes both dimensions.
Before reaching the judging panel, each model response passes through a conciseness gate with a generous threshold (3x ground truth length), filtering out responses that are excessively verbose before scoring begins. The three judges then vote independently across both accuracy and completeness. A majority vote of 2 out of 3 determines the final correctness label for each response. Conciseness acts as a prerequisite gate rather than a scored dimension, ensuring that only appropriately scoped answers are evaluated for factual correctness in the first place.
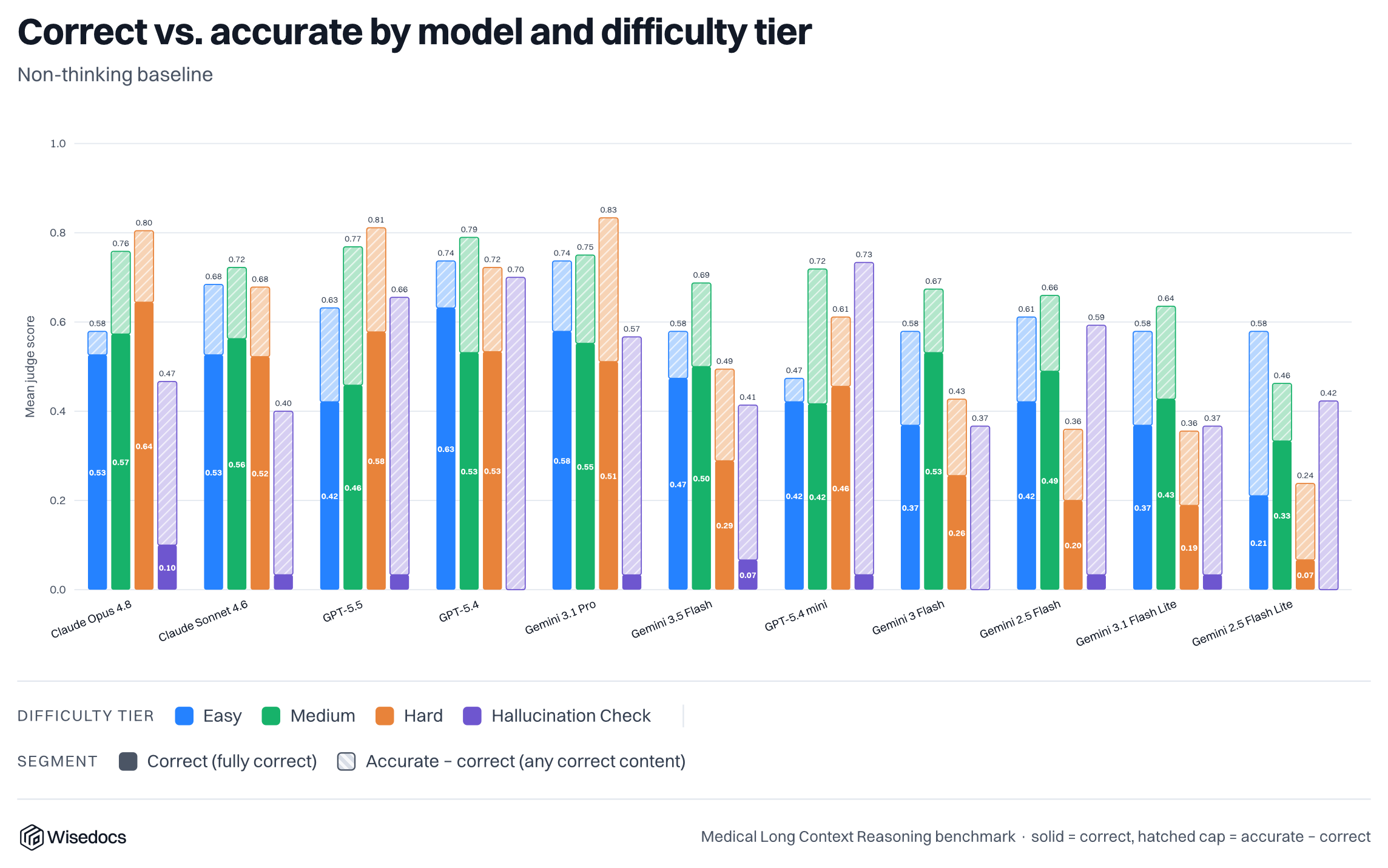
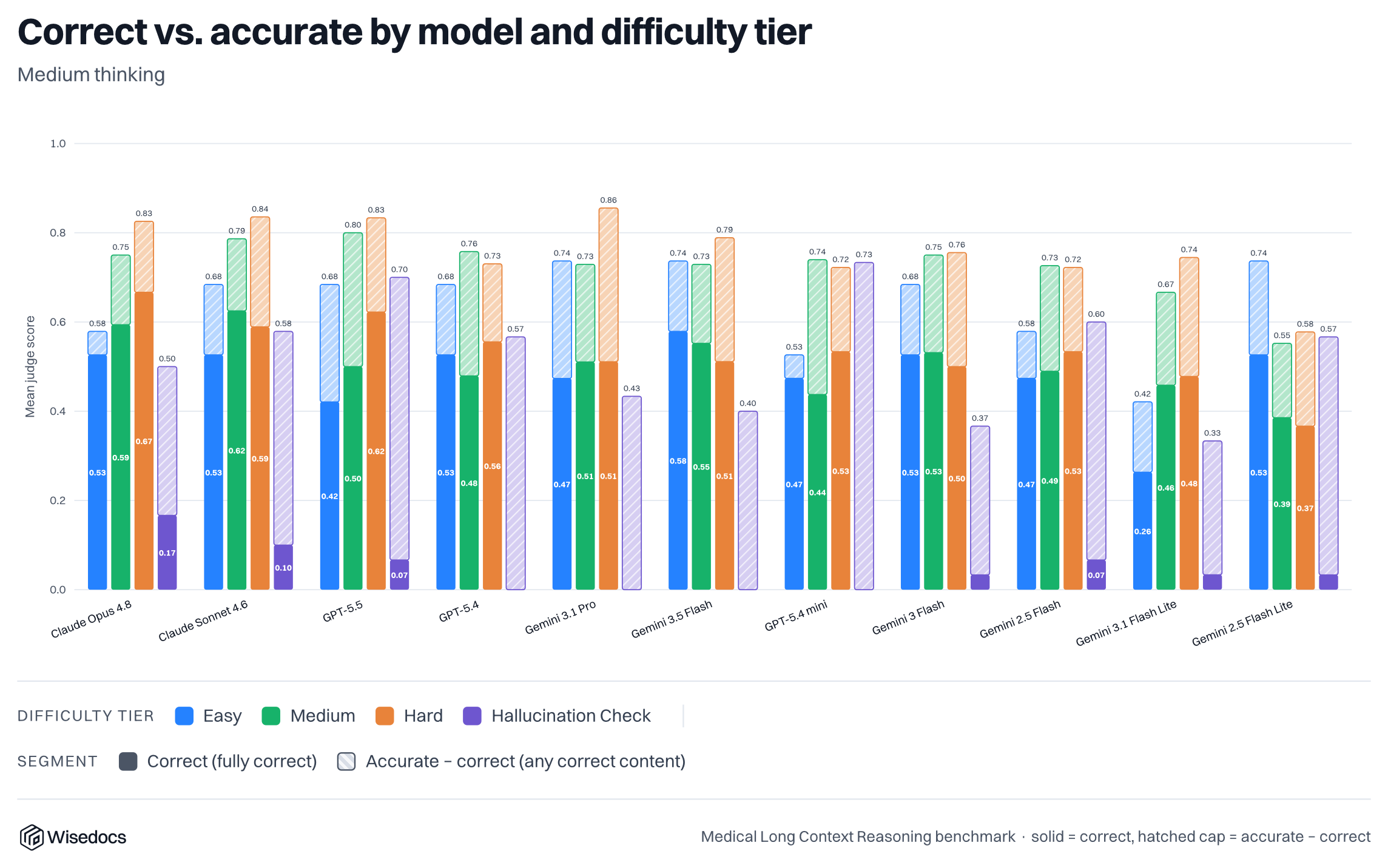
Measuring Model and Judge Variation
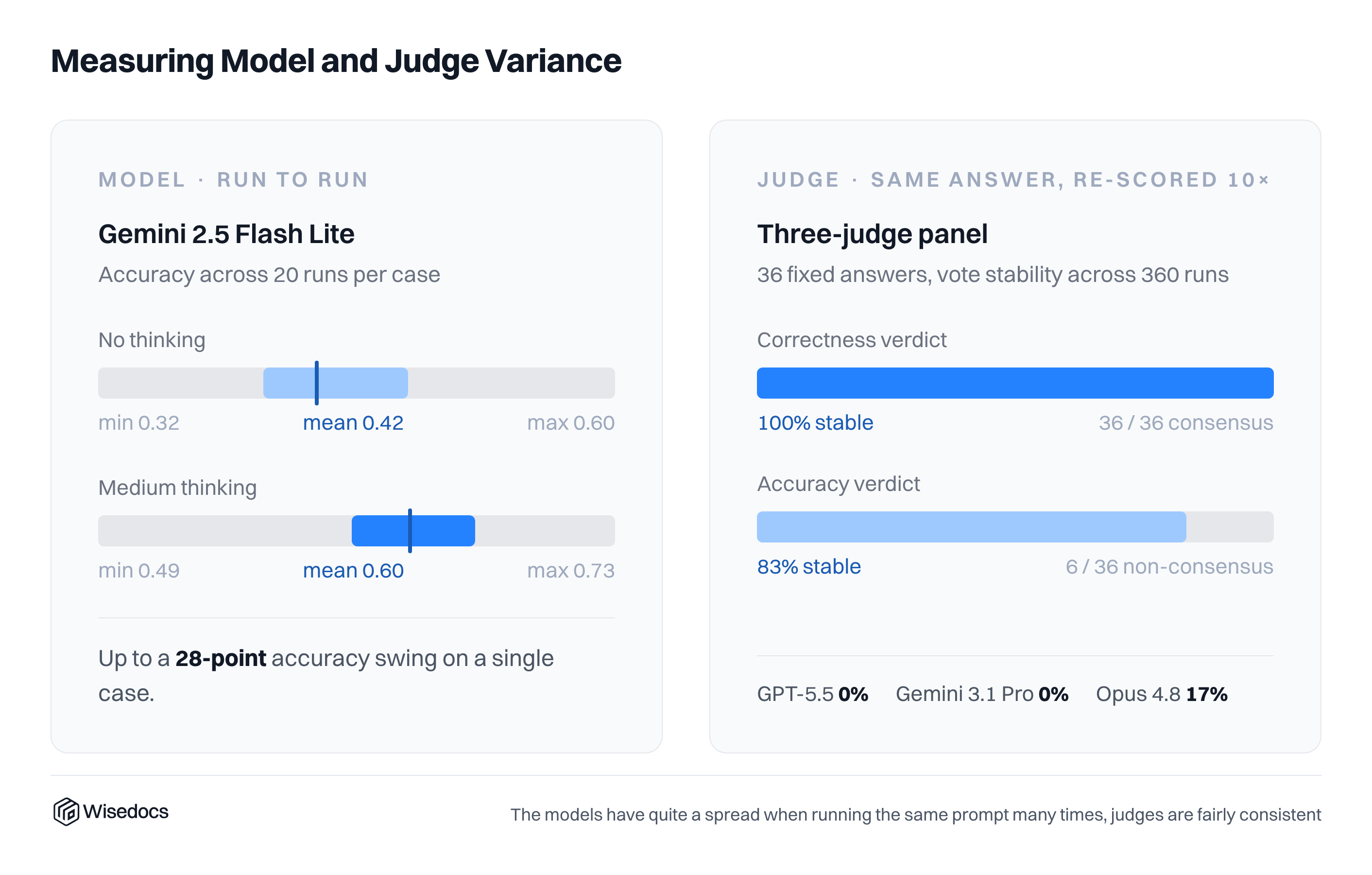
To measure model variation, we complete a number of evaluation runs and report the average, with the number of trials ranging between 3-20 depending on the model and experiment. For our model variation measurement, we focus Gemini 2.5 Flash Lite and run it across 20 cases, showing a large variation of potential answers. This variation does not decrease when thinking mode is enabled.
To measure judge variation, we measure 36 responses from two models and run them 10 times each for grading. We find correctness consensus, with some variation on Opus 4.8 for accuracy.
Filler Documents
After running our questions against clean cases, we added additional noise to measure the impact of plausible, but irrelevant context. We do this by interleaving unrelated medical and administrative forms into the real case context at configurable ratios. Our filler pool consists of 34 form types including CMS Medicare forms, Ontario Claims Forms, clinical notes, and vehicle inspection reports. Publicly accessible blank templates of these forms were automatically filled with realistic synthetic patient data using Nano Banana 2 for visual generation and the Python Faker library for identity synthesis (names, dates of birth, addresses, SSNs, insurance IDs, diagnosis codes, and more). For our text-based evaluations, the OCR transcripts of these filled forms serve as the filler pages.
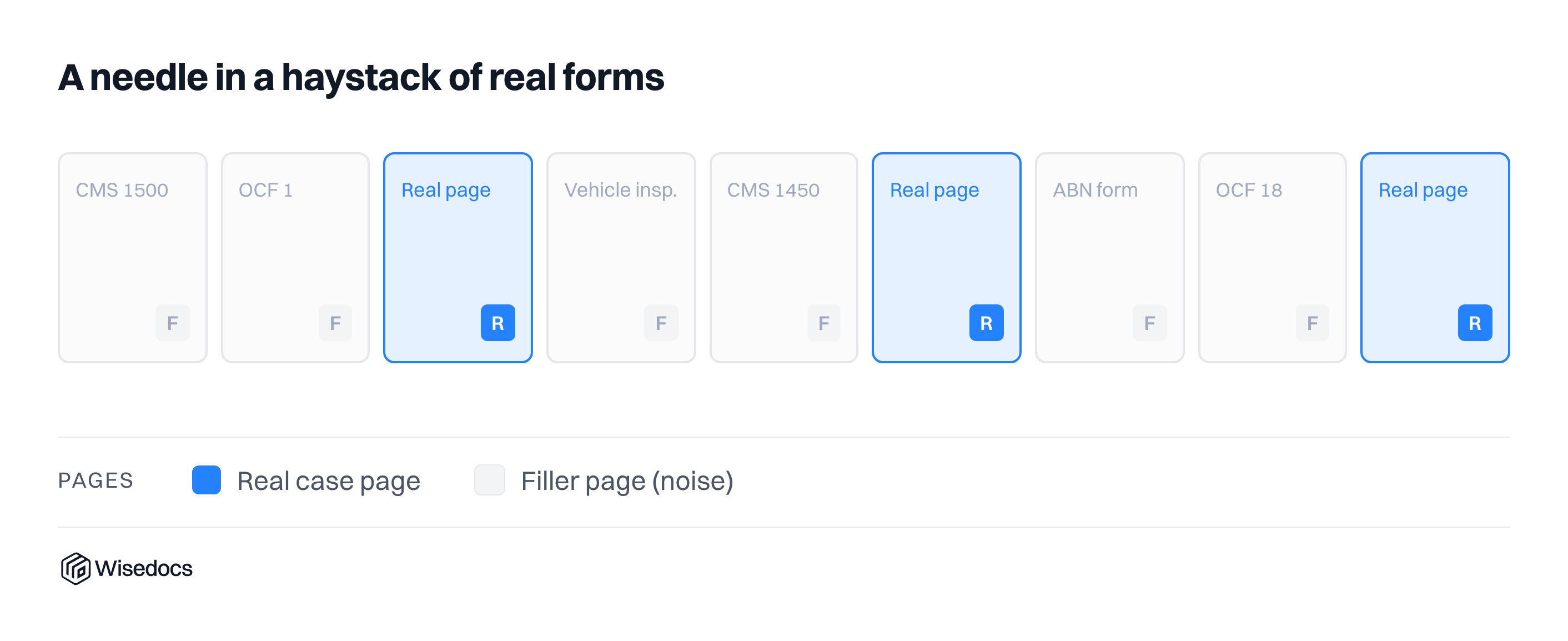
At runtime, given a junk_context_ratio (e.g. 4 means four filler pages per real page), we calculate the number of filler pages needed, sample them with replacement from the pool of forms, generates uniformly random insertion positions among the real document pages, and interleaves the filler text into the case context.
This process is based on a reproducible seed (1). This design lets us sweep multiple distraction levels in a single experiment and make fair comparisons across models, prompt difficulties and thinking modes, knowing each saw exactly the same noise.
Results
Creating the benchmark we had a series of questions we wanted to answer
- How well do models perform on clean medical summaries?
- How much does thinking impact the results and their stability?
- How much variation is there in model runs?
- How do models perform on difficult and compound questions?
- How does context window stuffing affect model reasoning capabilities?
Establishing a baseline
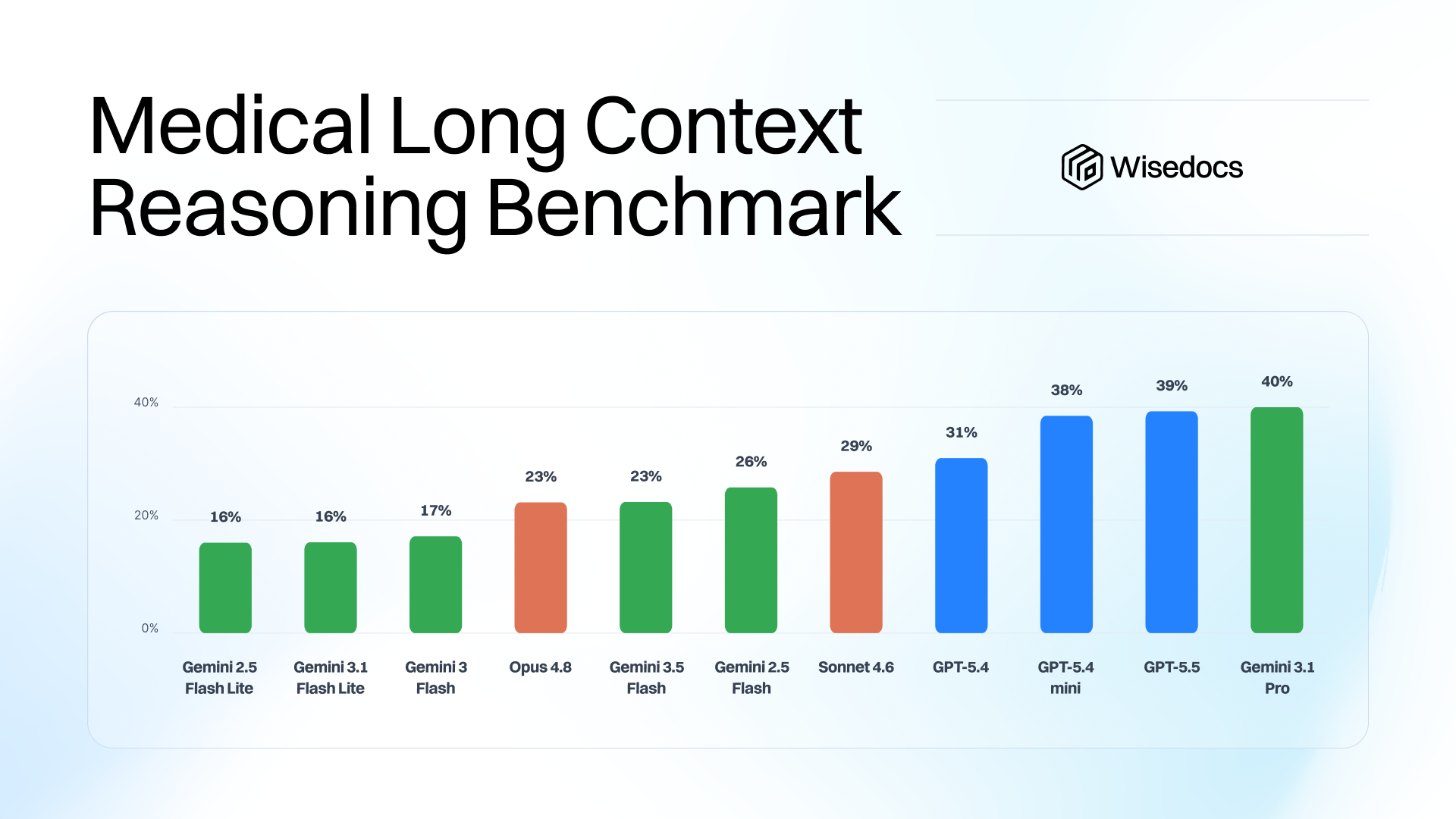
We tested our cases against 11 commercial models with two thinking modes, low and medium. We compare the accuracy against all questions and the two most challenging categories: Expert questions and Multipart Compound questions.
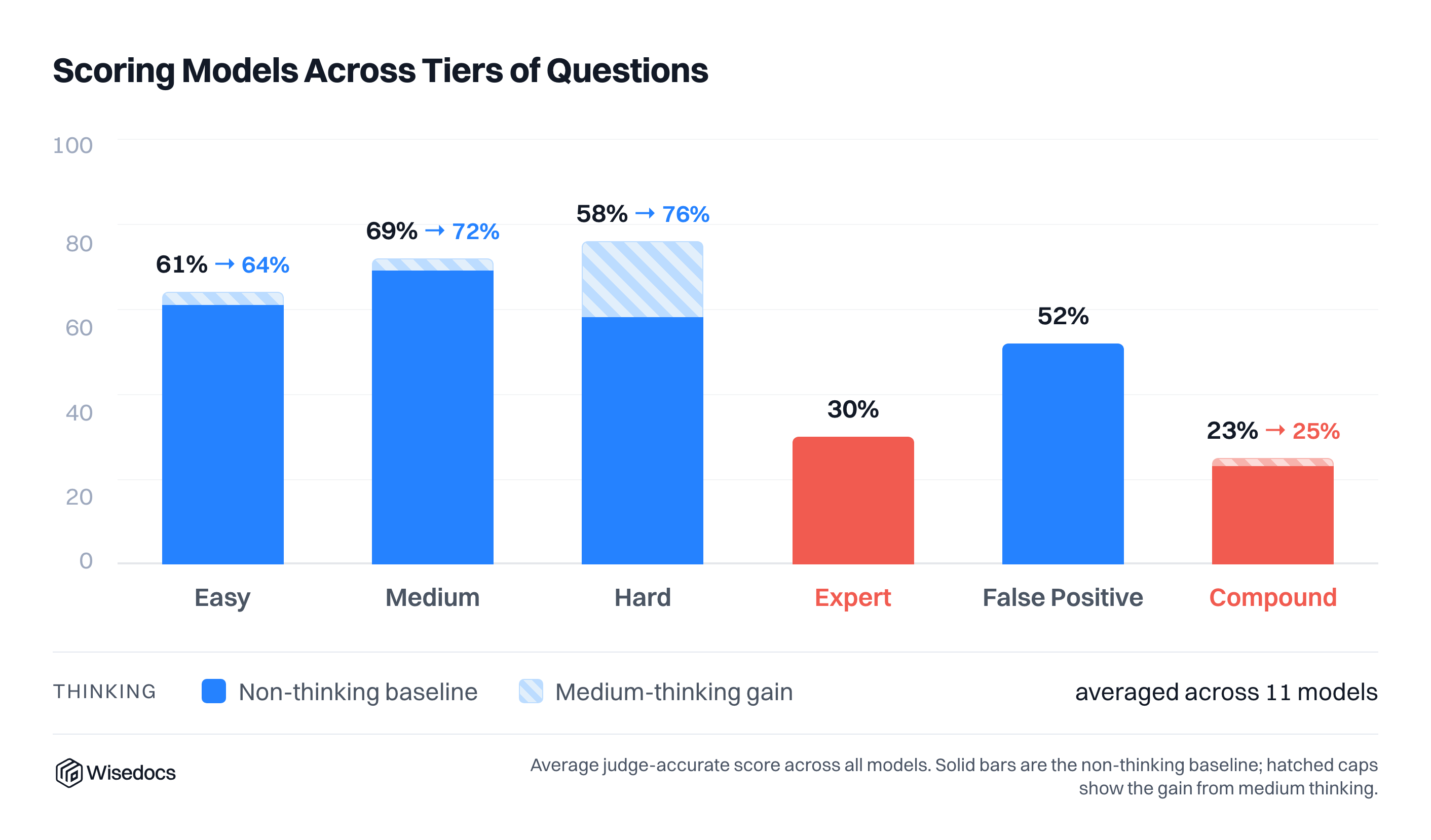
Thinking, surprisingly, did not make as large of an impact at the medium level as expected for the hardest questions, with some models showing improvements while others showed degradation with medium thinking.
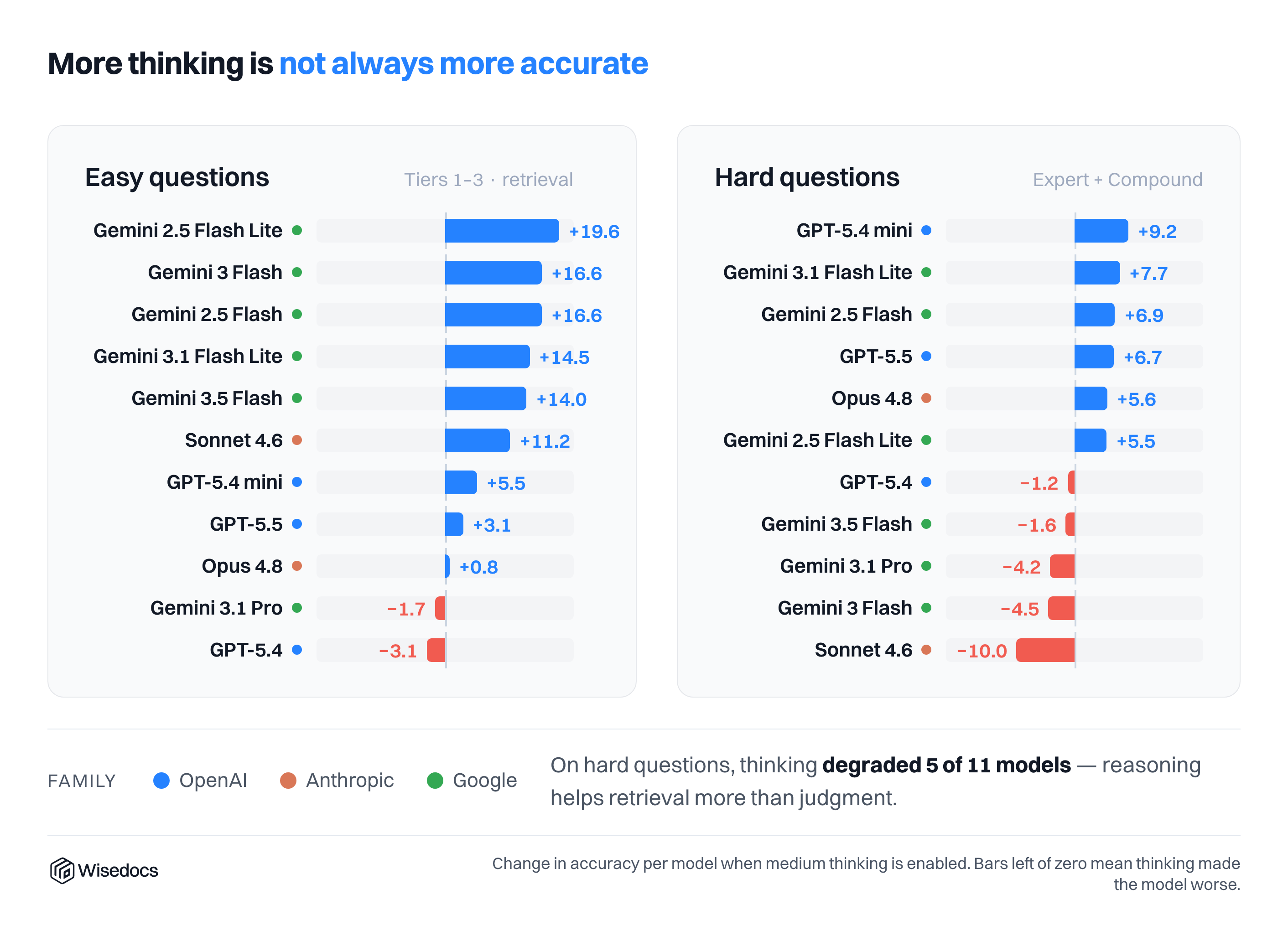
Question Difficulty
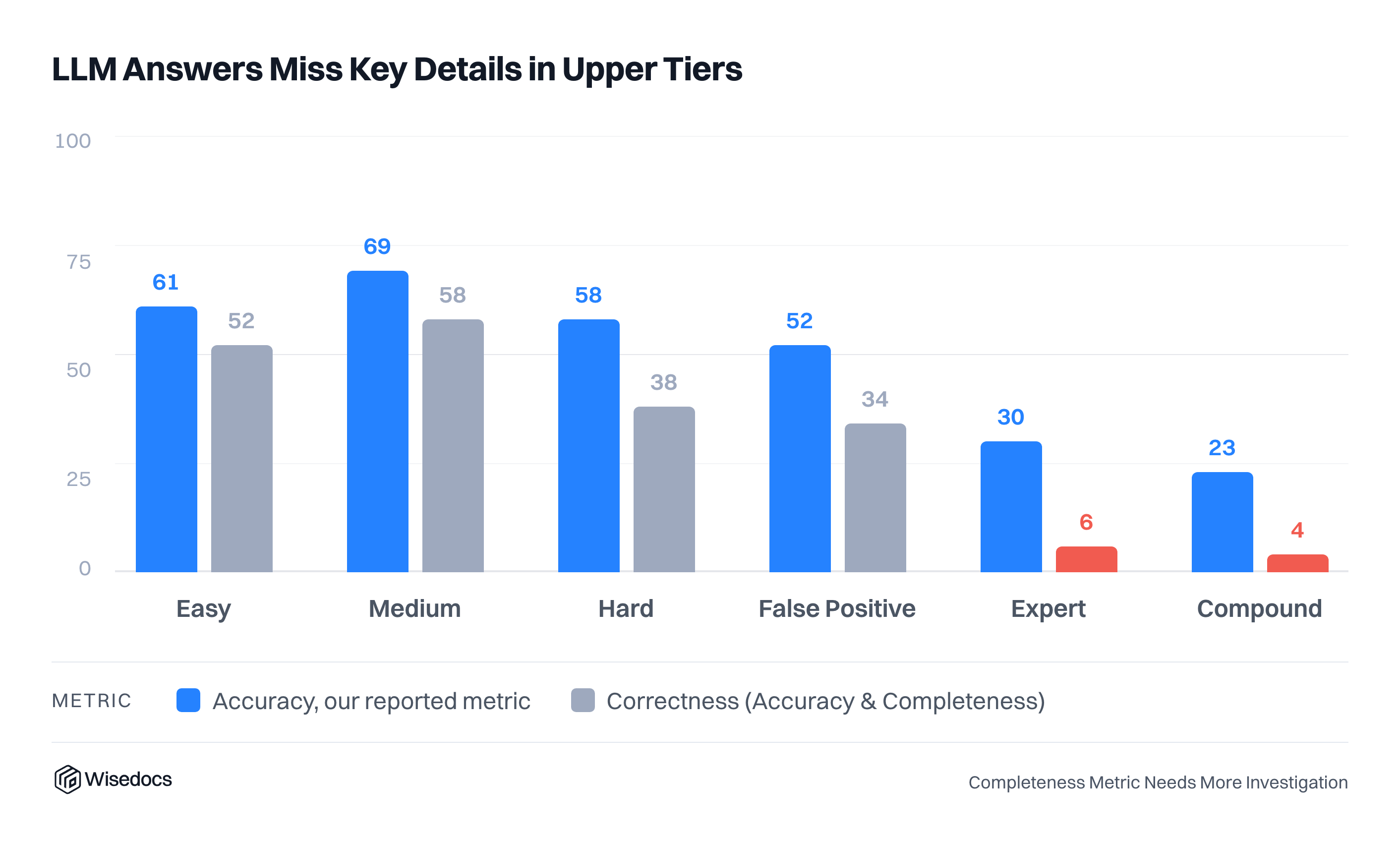
We compared the human-perceived difficulty against model results and found a consistent assessment of human tier questions and model results. Two results stood out: most models scored well on hard-tier questions with thinking enabled, and models were able to score higher than expected on the false positive tier (Tier 5)
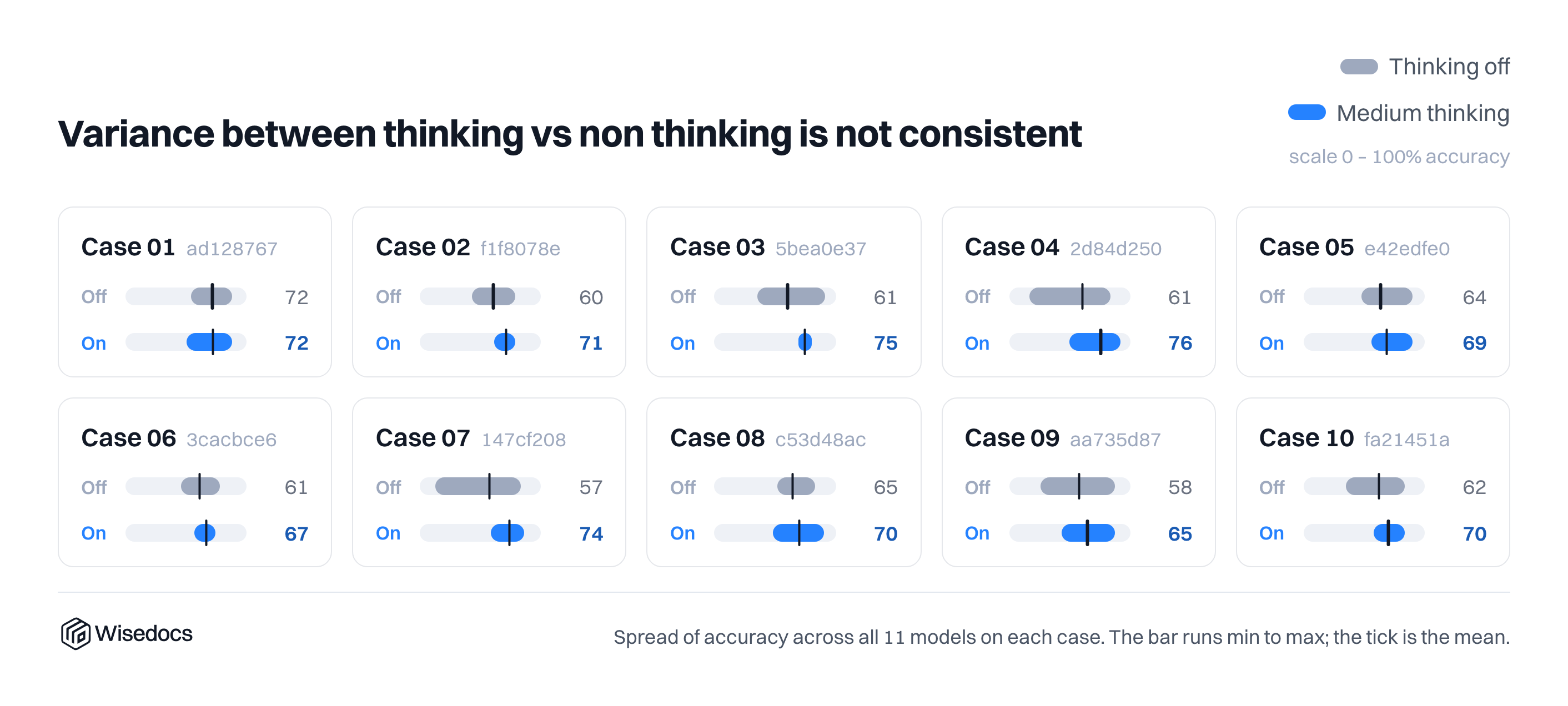
Answer Variance
With reasoning models defaulting to a temperature of 1, we measure the variance of the model results with thinking on and off. For Gemini 3.1 Flash Lite, the min/max range is pretty significant for this type of eval without a clear difference in variance with and without thinking tokens. We include error bars for our general runs to indicate this variance.
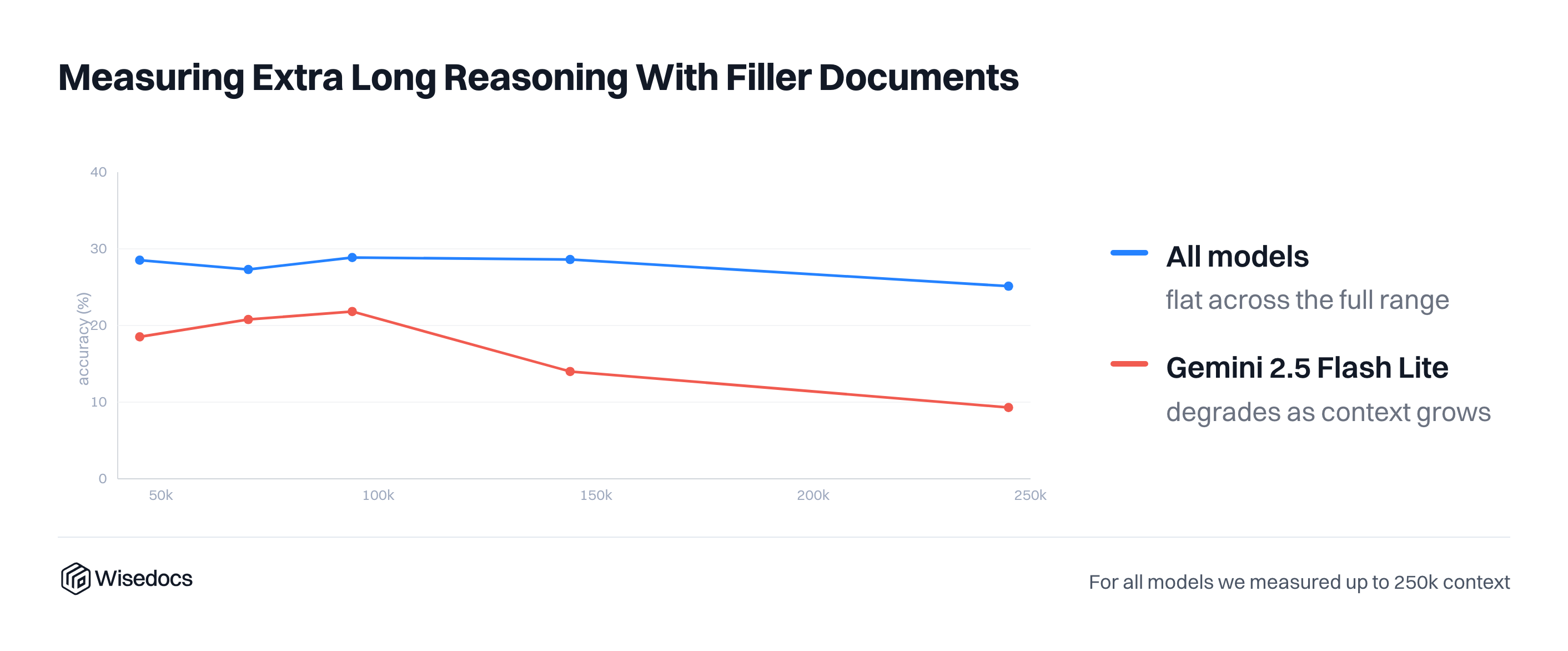
Context Window Filler
After introducing context filler, we noticed a small impact across models; the most significant impact was for smaller commercial models with thinking turned off.
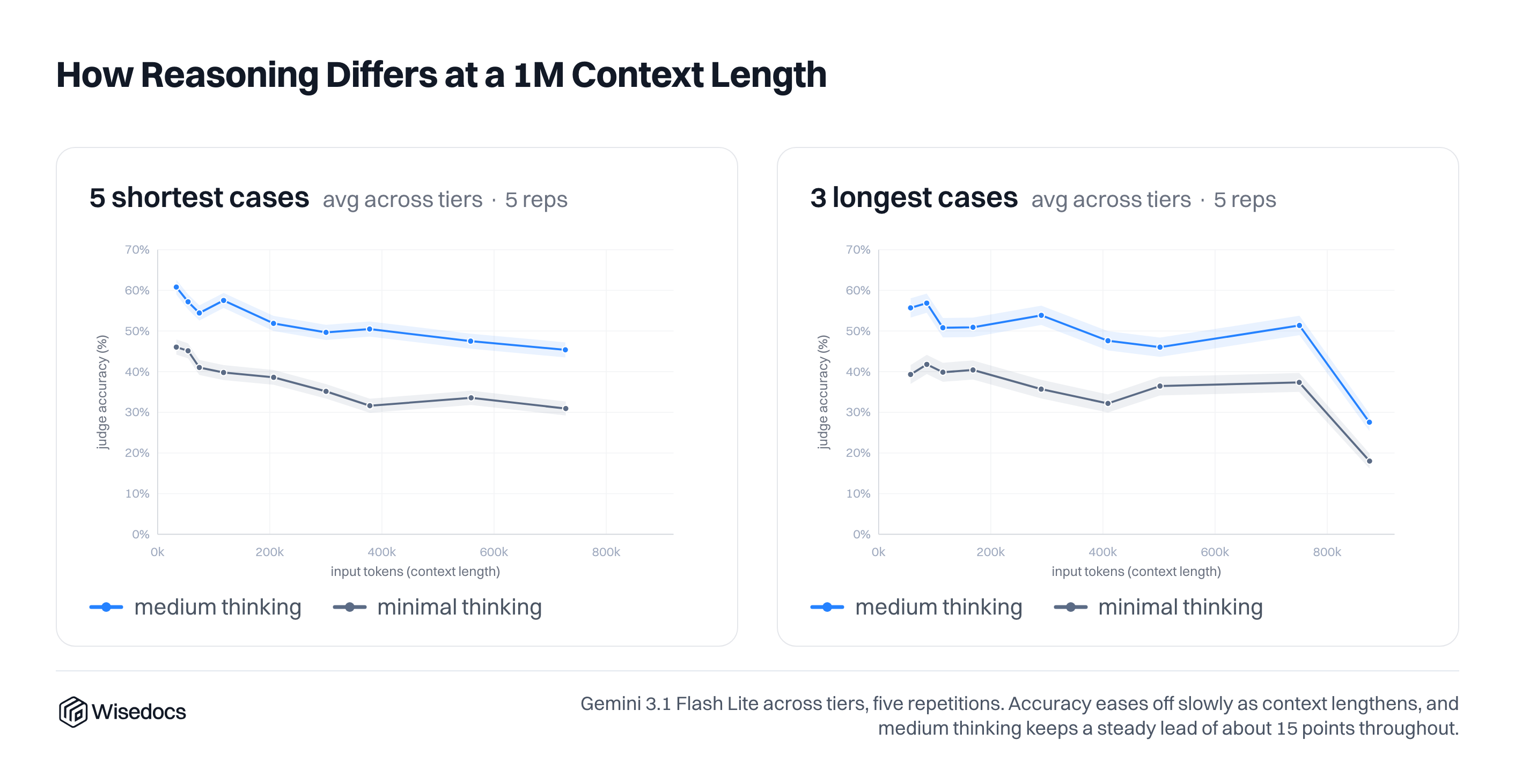
We ran an extended experiment for Gemini 3.1 Flash Lite, separating the most challenging and simple cases to see their impact. Looking at our cases, the shortest cases had the lowest accuracy, so a separation allowed us to see a clearer trend across context length. We also plot the variation of accuracy across 5 rounds of answer generation.
Models have gotten much stronger across generations on long context reasoning and haystack problems. For future releases we will include more challenging filler content of misleading or more complex information.
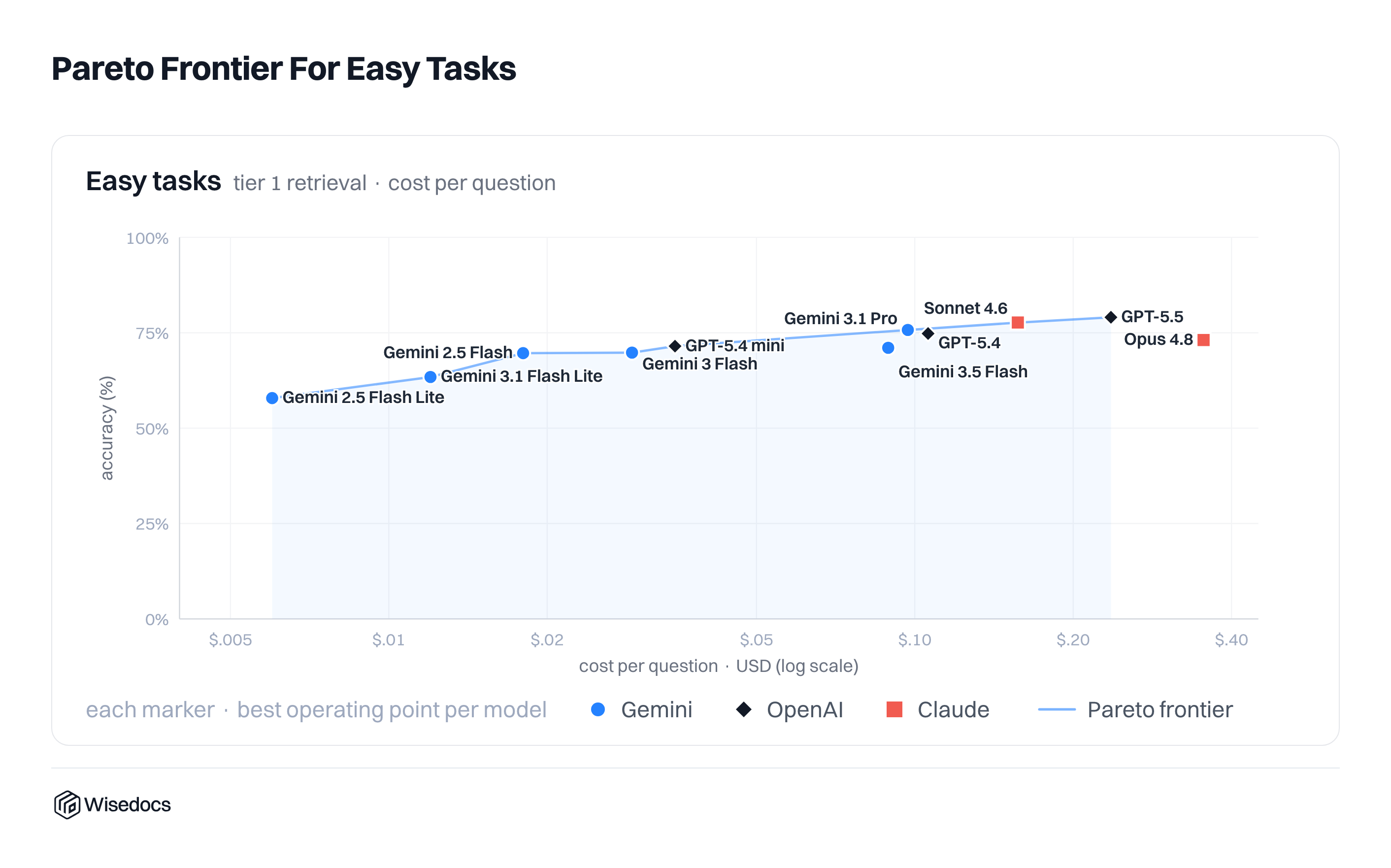
Cost Pareto Frontier
Finally we compare the cost and accuracy ratio of each model to find the Pareto optimal. For easy tasks, additional model costs and capabilities lead to a pretty strong trend with almost all models on the frontier.
For harder tasks, the frontier is a lot more sparse, with the Gemini models occupying the frontier except for a strong showing from GPT 5.4 mini.
.png)
Opensourcing the benchmark
We are opensourcing large parts of the benchmark to continue open research on complex document reasoning. The cases and Tier 1-3 question data are now available on Huggingface as well our testing harness on github. Tier 4-6 of questions will be hosted as a private eval on Artificial Analysis to avoid contamination.
Huggingface: https://huggingface.co/datasets/Wisedocs/mlcr-dataset
Github: https://github.com/Wisedocs-AI/medical-long-context-reasoning
Next Steps
As we continue to explore this problem of medical document knowledge work, we’ll be releasing updated versions of MLCR. Below are some of our intended research directions:
- Realistic documents containing information compared to document summaries
- Higher thinking modes measured
- Measuring tool call and skill usage for working with medical documents
- Integrated multi-modality across files utilizing text and image based documents
- Prompt iteration and position validation, similar to “traditional” needle-in-the-haystack problems
- Comparing the speed and cost of model results compared to human professionals
Appendix
- Our noise creation process is fully reproducible: a per-row random number generator is derived by hashing the experiment's global seed together with the case UUID and the ratio (blake2b(seed + ":" + case_uuid + "|" + ratio)), meaning the same case at the same ratio always receives identical filler regardless of which model, thinking level or prompt difficulty is being tested.
Related Work
Long-context reasoning benchmarks. Work on long-context evaluation has moved from simple retrieval toward more realistic tests of synthesis, aggregation, and multi-hop reasoning. Early broad suites such as LongBench established that long-context evaluation should span multiple task families: single- and multi-document QA, summarization, code, and aggregation [1]. L-Eval made a complementary methodological point: long-context evaluation also requires scoring methods that better align with human judgments, motivating the use of LLM-based judges [2]. More recent benchmarks have increased both context length and task difficulty. For example, InfiniteBench extended evaluation beyond 100K tokens [3], while LongBench v2 emphasized deeper reasoning over realistic long-context multitasks drawn from varied professional domains [4]. Furthermore, long-context reasoning benchmarks from Artificial Analysis found that even leading AI models from mid-2024 achieved less than 50% accuracy when tasked with synthesizing information spread across large contexts and understanding domain-specific content. This highlights how challenging it remains for large language models to reliably connect disparate pieces of information within extensive contexts [5].
A closely related line of work studies how the placement of relevant information within long inputs affects model performance. Lost in the Middle showed that even models explicitly designed for long contexts rely disproportionately on information near the beginning and end of the prompt, with substantial degradation when key evidence appears in the middle [6]. This finding is especially important because many real long-document tasks are not merely “find a fact” problems; they require combining multiple facts whose locations are unpredictable. Through its graded question-difficulty tiers, MLCR can test not only whether a model can retrieve a single “needle” from a haystack, but also whether it can reconstruct a clinically and administratively meaningful patient story spread across dozens of visits and interleaved noise pages.
Medical LLM and clinical-document benchmarks. Medical LLM evaluation has so far been dominated by exam-style and short-form QA benchmarks. Datasets like PubMedQA remain important because they test biomedical reasoning over research texts, including situations where quantitative context is relevant [7]. Benchmarks like MultiMedQA further offered a comprehensive question-answering benchmark in medical contexts that helped evaluate clinical knowledge, research and safety [8]. These benchmarks and datasets are all valuable, but they mostly evaluate either closed-book medical knowledge or short-form question answering. They generally do not require models to derive answers from a long patient record, track chronology across many visits, or determine whether an apparently plausible detail is actually undocumented in the chart.
Clinical-document benchmarks come closer to MLCR’s target setting. MIMIC-IV-Note provides the deidentified, structured, and note-based substrates that made research in this domain possible, including long-form discharge summaries and radiology reports [9]. EHRNoteQA is perhaps the clearest direct precursor: it evaluates clinically relevant questions over accumulated discharge summaries and includes both open-ended and multiple-choice versions with clinician review [10]. Yet even in this closer literature, the dominant settings are note-level QA, summarization, or structured prediction. They typically use shorter records than MLCR, focus on discharge-summary bundles rather than longitudinal claims-style case narratives, and do not systematically stress-test models with OCR-derived irrelevant medical and administrative forms inserted to fill the context window.
Hallucination and evaluation methodology. A separate but highly relevant literature studies hallucination, factuality, and benchmark scoring. In medicine, MedHalu demonstrates that LLMs may struggle to detect unsupported or fabricated medical content, especially when misinformation is semantically close to the truth or when health queries are realistic and noisy [11]. In long-form generation, FActScore argues that factuality should be assessed at the level of atomic supported claims rather than relying on coarse output-level judgments [12]. MLCR’s Tier 6 differs from these settings in an important way: instead of asking whether an entire answer is hallucinated, it embeds both answerable and unanswerable sub-questions in the same claims-style prompt. The model therefore must do something subtler than global refusal or global answering: it must answer the supported part and abstain on the unsupported part. That is much closer to the failure mode practitioners care about when reviewing real records.
Since MLCR contains open-ended answers, its evaluation protocol also belongs in the related-work discussion. MT-Bench/Chatbot Arena, and later LLM-judge work showed that rubric-guided LLM evaluation can correlate reasonably well with human assessment at scale, but also documented important bias sources, including verbosity bias, positional bias, self-preference, and model-family “narcissism” [13]. Length-Controlled AlpacaEval and subsequent work made clear that judge outputs can be manipulated by style and length unless explicitly controlled [14]. In a medical benchmark, these cautions matter even more, because fluent but subtly unsafe answers may look superficially strong. MLCR’s use of a panel of heterogeneous judges, majority voting, conciseness gating, and calibration against human-validated answers is therefore well aligned with the best lessons from the evaluation-methods literature.
Positioning of MLCR. The most precise way to position MLCR is as a benchmark for long-context, longitudinal, noisy, medically grounded document reasoning. Existing long-context benchmarks establish that retrieval is not enough and that models degrade with longer contexts and information-position effects, but they usually lack medical realism. Existing medical benchmarks establish that frontier models can score well on exams, abstracts, consumer questions, and even some open-ended healthcare tasks, but they usually do not require reconstructing a longitudinal timeline across many visits in a record-like setting. Existing EHR-note benchmarks are closer, especially EHRNoteQA, yet they generally do not stress claims-style chronology, difficulty-tiered synthesis, or explicit irrelevant form noise.
MLCR therefore fills a specific gap. It combines long-context medical case reasoning, difficulty-tiered claims questions, synthetic but realistic longitudinal cases, context-window filler experiments, compound hallucination checks that require partial abstention, and rubric-based LLM judging calibrated to human-validated answers. This combination, not any single ingredient, is what makes MLCR a distinct contribution. It offers a benchmark to evaluate model understanding and reasoning over long-context, longitudinal claims-style medical information.
[1] Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y., Tang, J., & Li, J. (2024). Longbench: A bilingual, multitask benchmark for long context understanding. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3119–3137. https://doi.org/10.18653/v1/2024.acl-long.172
[2] An, C., Gong, S., Zhong, M., Zhao, X., Li, M., Zhang, J., Kong, L., & Qiu, X. (2024). L-eval: Instituting standardized evaluation for long context language models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 14388–14411. https://doi.org/10.18653/v1/2024.acl-long.776
[3] Zhang, X., Chen, Y., Hu, S., Xu, Z., Chen, J., Hao, M., Han, X., Thai, Z., Wang, S., Liu, Z., & Sun, M. (2024). ∞bench: Extending long context evaluation beyond 100K tokens. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 15262–15277. https://doi.org/10.18653/v1/2024.acl-long.814
[4] Bai, Y., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y., Tang, J., & Li, J. (2025). Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 3639–3664. https://doi.org/10.18653/v1/2025.acl-long.183
[5] Artificial Analysis. (n.d.). Artificial Analysis long context reasoning benchmark leaderboard. Artificial Analysis.
https://artificialanalysis.ai/evaluations/artificial-analysis-long-context-reasoning
[6] Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12, 157–173. https://doi.org/10.1162/tacl_a_00638
[7] Jin, Q., Dhingra, B., Liu, Z., Cohen, W., & Lu, X. (2019). PubMedQA: A dataset for Biomedical Research Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2567–2577. https://doi.org/10.18653/v1/d19-1259
[8] Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., Payne, P., Seneviratne, M., Gamble, P., Kelly, C., Babiker, A., Schärli, N., Chowdhery, A., Mansfield, P., Demner-Fushman, D., … Natarajan, V. (2023). Large language models encode clinical knowledge. Nature, 620(7972), 172–180. https://doi.org/10.1038/s41586-023-06291-2
[9] Johnson, A., Pollard, T., Horng, S., Celi, L. A., & Mark, R. (2023). MIMIC-IV-Note: Deidentified free-text clinical notes (version 2.2). PhysioNet. RRID:SCR_007345. https://doi.org/10.13026/1n74-ne17
[10] Cha, D., Choi, E., Kim, J., Kim, K., Kwak, H., Kweon, S., Won, S., Yang, J., & Yoon, H. (2024). EHRNoteQA: An LLM benchmark for real-world clinical practice using discharge summaries. Advances in Neural Information Processing Systems 37, 124575–124611. https://doi.org/10.52202/079017-3958
[11] Agarwal, V., Jin, Y., Chandra, M., De Choudhury, M., Kumar, S., & Sastry, N. (2026). Medhalu: Hallucinations in responses to healthcare queries by large language models. Proceedings of the International AAAI Conference on Web and Social Media, 20(1), 31–44. https://doi.org/10.1609/icwsm.v20i1.42623
[12] Min, S., Krishna, K., Lyu, X., Lewis, M., Yih, W., Koh, P., Iyyer, M., Zettlemoyer, L., & Hajishirzi, H. (2023). FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 12076–12100. https://doi.org/10.18653/v1/2023.emnlp-main.741
[13] Chiang, W.-L., Gonzalez, J., Li, D., Li, Z., Lin, Z., Sheng, Y., Stoica, I., Wu, Z., Xing, E., Zhang, H., Zheng, L., Zhuang, S., & Zhuang, Y. (2023). Judging LLM-as-a-judge with MT-bench and Chatbot Arena. Advances in Neural Information Processing Systems 36, 46595–46623. https://doi.org/10.52202/075280-2020
[14] Dubois, Y., Galambosi, B., Liang, P., & Hashimoto, T. B. (2024). Length-controlled AlpacaEval: A simple way to debias automatic evaluators (arXiv:2404.04475). arXiv. https://doi.org/10.48550/arXiv.2404.04475

.png)