.png)
We're excited to bring Agentic Document Verification using Claude Managed Agents to Wisedocs. These Quality Assurance (QA) Agents verify the correctness of documents generated by our insights engine, saving our Medical Quality Assurance team up to 50% of their document review cycle time.
Usecase Overview
At Wisedocs, we focus on helping teams handle complex medical claims, where our customers often upload a massive volume of PDFs (50,000+) for analysis which can contain over 1500+ distinct document types. One of our AI team’s responsibilities is structuring this document information as the first part of the claims process.
We’ve spent the past 2 years building our ML and Expert HITL systems for document processing and we are constantly trying to re-imagine what the future could look like. When the opportunity arose to explore Managed Agents through the Early Access Program, we were excited to give it a try to see where we could find the most value. In this blog post, we’ll share our experience of the product’s capabilities: what can be prototyped in an afternoon and shipped in a week.
We chose to focus our experiments on our quality verification, where we audit our system results.
Agentic QA Automation Overview
Within Wisedocs, we have a three-stage verification process: AI verification, expert-in-the-loop verification, and QA cross-reference. The QA cross-reference is an essential part to ensure our customer’s success with high quality data. The process involves weekly human review to find disagreement between internal experts and our models, making judgement calls with corrections, and creating reports for review between our ML and Document experts teams.

To speed up this process and catch more issues, we built a Claude Managed QA Agent with four main steps:
- Randomly select documents based on QA requirements
- Cross-reference the documents against their document-specific Standard Operating Procedures (SOPs)
- Conduct an analysis consistent with our experts' methodology and produce a report
- Allow experts to verify the Agentic QA reports before the process is finalized

With Claude Managed Agents, we were able to reach several milestones rapidly:
- An initial prototype in 2 hours
- An internal beta test within 3 days
- Full product development within a week
We used three main features: the core Managed Agents API, Memory, and Outcome Rubrics.
Managed Agents API Setup
We built our first prototype in a few hours by combining our document verification guidelines, document API, and the Claude Skills provided as part of the Managed Agents API. When creating our Managed Agent, we pass a series of Markdown Guideline files, a PDF-editing skill, the document to audit (500 pages), and the extracted document results. The output was a page-by-page analysis in both a markdown summary format and a structured csv.

The first Managed Agent we ran had a 29 minute session to output the results, with Sonnet 4.6. We examined the performance and began implementing the additional primitives available to us to enrich the capabilities of our QA Agent for a broader vision of unifying human and AI standards.
Leveraging Memory
We used memory to maintain a list of common issues and edge cases that different agent instances could read and write to during runtime. For example, the CMS1500 form — a standard healthcare claim — could be classified as form document type or a finance document type, depending on how you define your guidelines. Internally, we classify it as a finance document given the billing information, but many models initially predict it as a form. This type of edge case exists across thousands of document types and fields that need specific instructions that we’ve defined over the years. As part of our agent setup, we prompted the Agents to create a list of edge cases that we could review.

After running the QA Audit Agent, we reviewed the recommended guideline updates, and corrected any mistakes that the AI agent made.
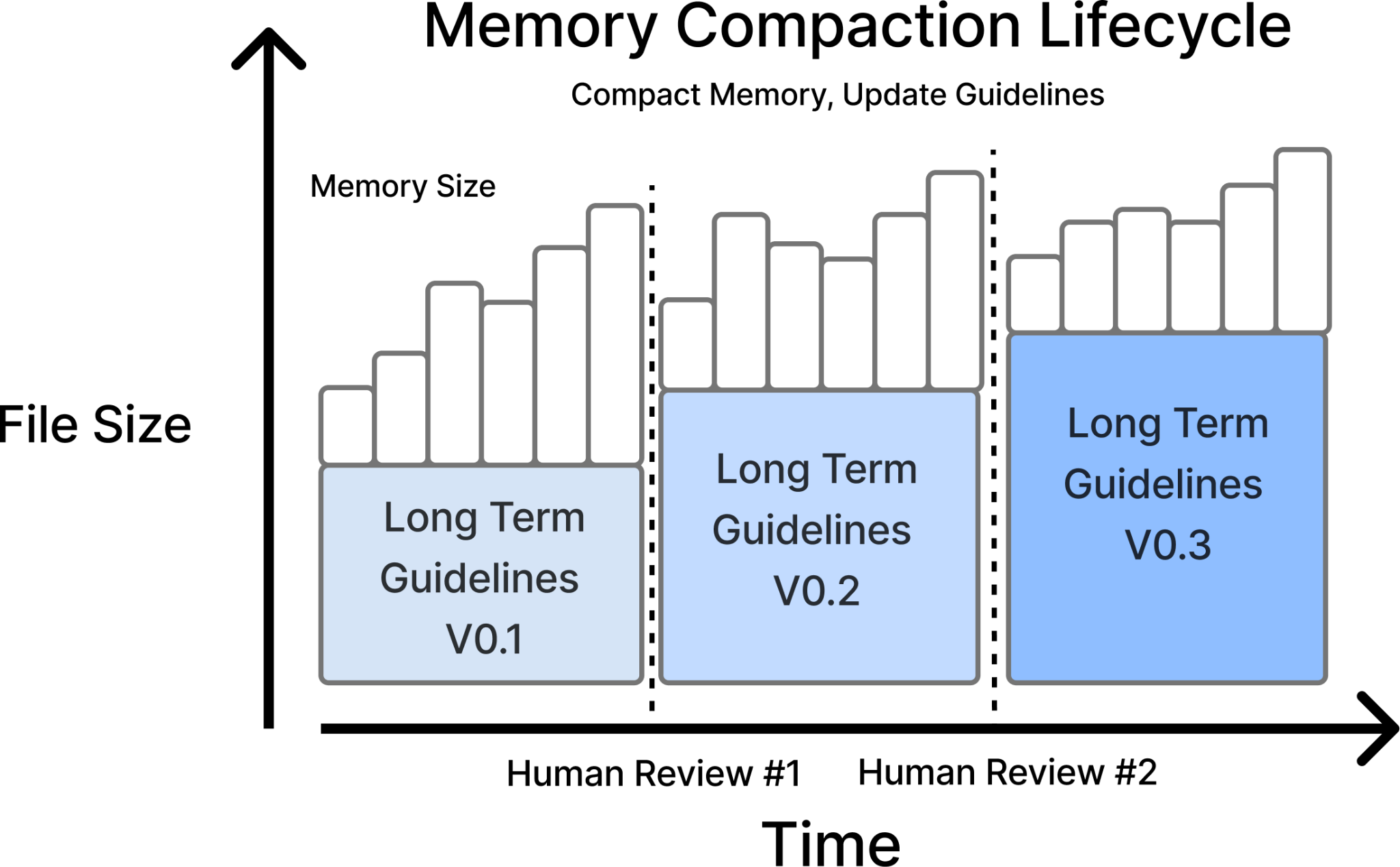
We chose to use the memory functionality as the main method of sharing context between agents, and track how models classify results. We review these mistakes on a regular basis to make sure we don’t have cascading errors by the AI Agent. We also utilized the memory to identify gaps for improving future human training. With this iterated lifecycle, we made significant progress to align our AI Agents and Human Experts guidelines.
Using Defined Outcome Rubrics
To ensure our QA Audit Agent outputs matched our guidelines and formatting expectations, we introduced outcome rubrics as another quality gate.
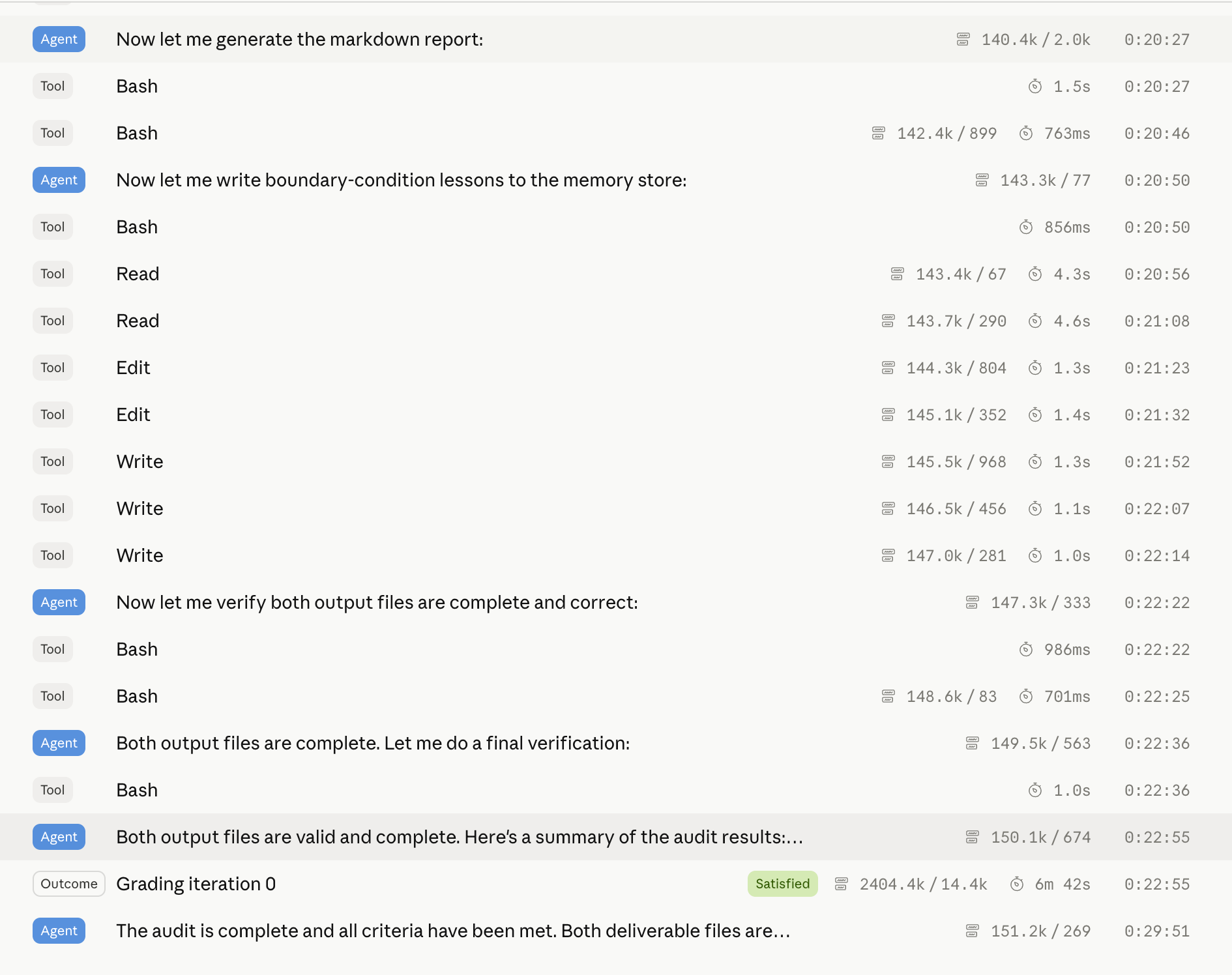
Our rubrics focused on our SOP guidelines with some additional formatting validation. We typically succeeded within 1 iteration, which minimized both latency and cost.
Considering Managed Agents For Primary Inference
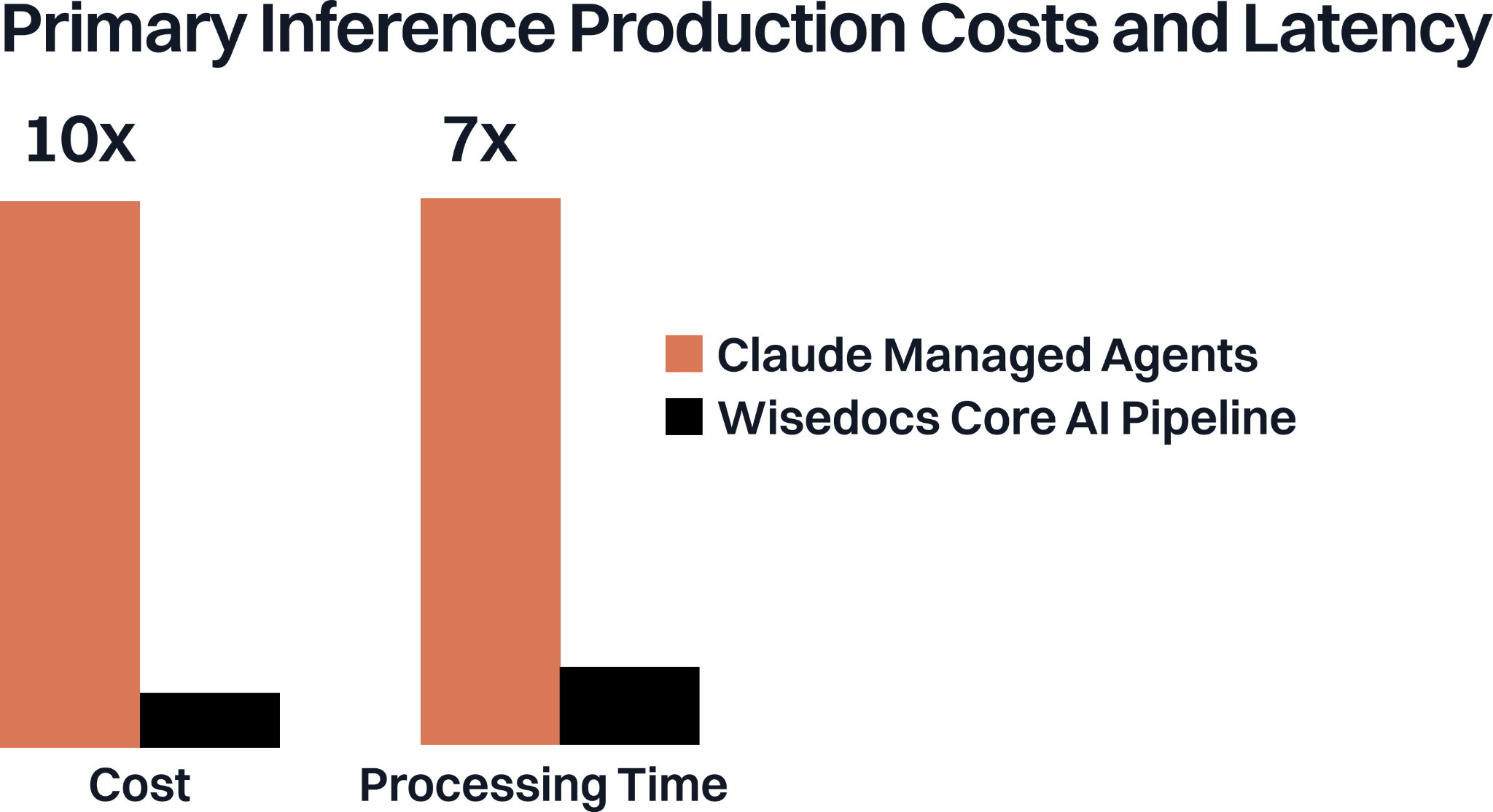
As we were building with Managed Agents we considered running it as our primary pipeline for document processing, with our core metrics being cost, accuracy and processing time. We compared how our Managed Agent performed against our expert team and our core AI pipeline with four setups:
- Our Core AI Pipeline
- Expert in the Loop Verification
- Managed Agents
- Managed Agents + Expert Verification
Managed Agents was much faster to iterate on and allowed more dynamic workflows, but it was more expensive and slower than our current setup with our pipeline processing documents 7x faster than Managed Agents roughly 1/10th the cost. Given our low customer turnaround times constraints and cost structure, we opted to run Managed Agents as our auditing third line of defense, leveraging its strengths for the right use case. While more expensive, Managed Agents provided us with more flexibility in design, deployment and agentic capabilities such as defining guidelines, file cross reference, memory updates.
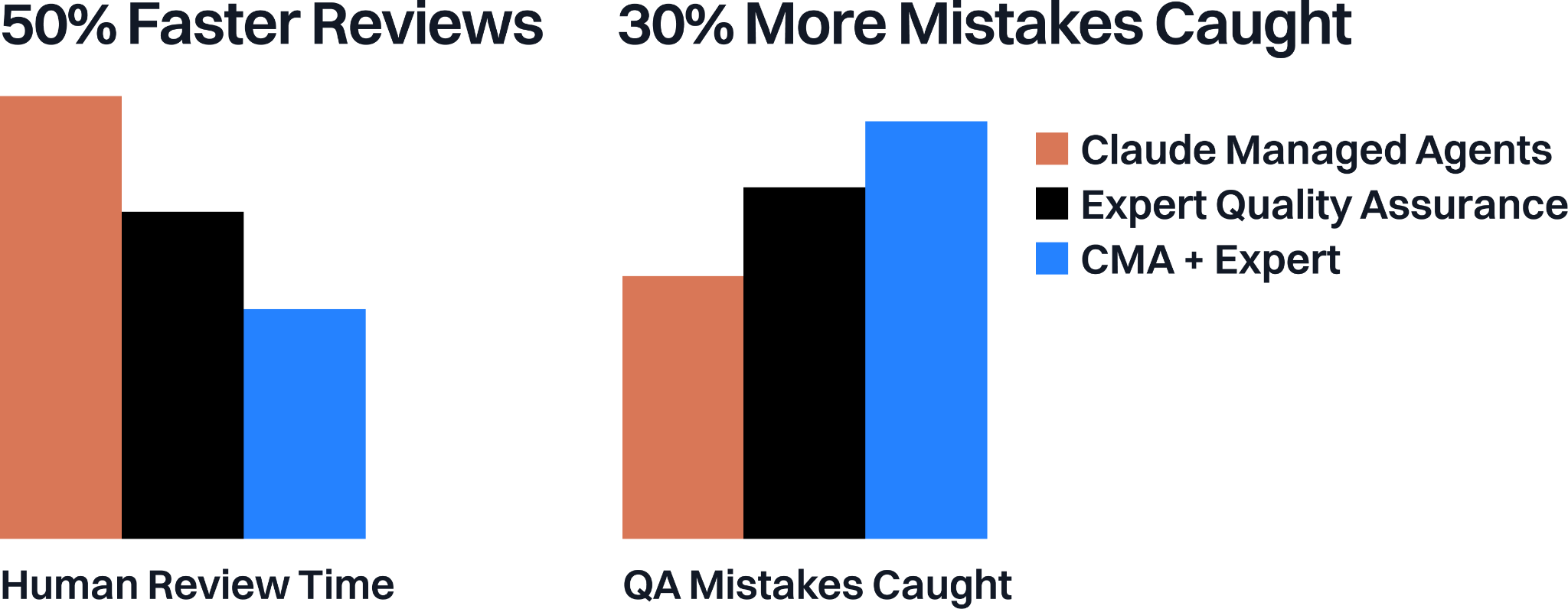
Combining Managed Agents with our Quality Auditors was a major unlock for our team. As a baseline we compared the Managed Agent with our QA auditors, and the Human completed document verification roughly 30% faster and caught 20% more mistakes. With a combined human and AI system, auditors were able to achieve 50% faster audits on a given file and catch 30% more mistakes compared to the human baseline.
We see our core AI systems along with Managed Agents as complementary builds, allowing us to ship faster, raise quality standards, and improve our customer experience.

.png)